

[et_pb_section fb_built=”1″ admin_label=”section” _builder_version=”4.16″ global_colors_info=”{}”][et_pb_row admin_label=”row” _builder_version=”4.16″ background_size=”initial” background_position=”top_left” background_repeat=”repeat” global_colors_info=”{}”][et_pb_column type=”4_4″ _builder_version=”4.16″ custom_padding=”|||” global_colors_info=”{}” custom_padding__hover=”|||”][et_pb_text admin_label=”Text” _builder_version=”4.19.5″ background_size=”initial” background_position=”top_left” background_repeat=”repeat” custom_padding=”||1px|||” global_colors_info=”{}”]
RAMAN: Introduction:
Deep neural networks (DNNs) have been ubiquitous in various cognition and learning problems. Traditionally, DNN computations are performed in the cloud, with the results transmitted back to edge devices. However, this approach introduces delays due to limited communication bandwidth. As a result, there is a growing interest in deploying DNNs directly on edge devices to leverage benefits such as privacy, bandwidth savings, and reduced latency. Nevertheless, executing DNN computations on edge devices presents challenges due to power, memory, and resource constraints. To address these edge computing bottlenecks, we propose RAMAN, a Re-configurable and spArse tinyML Accelerator for infereNce on edge.
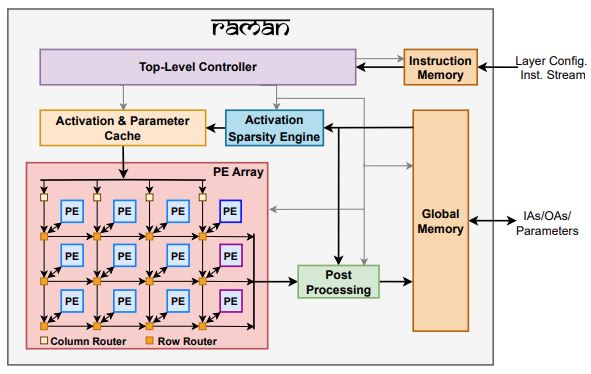
Figure 1: Top-level architecture
The key features of the RAMAN accelerator are:
Sparsity: RAMAN leverages activation and weight sparsity in (a) Reducing latency by skipping the processing cycles with zero data, (b) Reducing storage by pruning and compressing the model parameters at the compile-time, and (c) reducing data movement by exclusively accessing the non-zero data from memory.
Programmability: RAMAN supports a wide range of layer computations, including traditional CNN networks and modern depth-wise separable convolutions constituting depth-wise and point-wise layers. Our design also enables on-chip residual additions, fully connected layers, average pooling, and max pooling operations, eliminating the need for off-chip computation and communication.
Dataflow: RAMAN incorporates novel dataflow inspired by Gustavson‘s algorithm that has optimal input activation (IA) and output activation (OA) reuse to minimize memory access and the overall data movement cost. The dataflow allows RAMAN to reduce the partial sum (Psum) locally within a processing element array to eliminate the Psum writeback traffic.
Memory storage reduction: RAMAN exclusively employs an on-chip memory to store activations and weights. The memory size of the on-chip SRAM is limited due to area constraints, which necessitates model optimizations to fit modern networks such as MobileNets in SRAM. RAMAN employs a hardware-aware pruning strategy to shrink the model size and intelligent memory scheduling to minimize peak activation memory to accommodate parameters and activations on-chip.
Demo:
We have successfully demonstrated the RAMAN accelerator for audio inference. A demonstration video on the Efinix Ti60 FPGA board for the keyword spotting task, where the user’s spoken keywords control the maze game, can be found here: https://youtu.be/sCksj7nlBY8.
Paper reference:
- Krishna, S. R. Nudurupati, D. G. Chandana, P. Dwivedi, A. van Schaik, M. Mehendale, and C. S. Thakur, “RAMAN: A Re-configurable and Sparse tinyML Accelerator for Inference on Edge,” 2023. [Online]. Availablehttps://arxiv.org/abs/2306.06493.
[/et_pb_text][/et_pb_column][/et_pb_row][/et_pb_section]