")
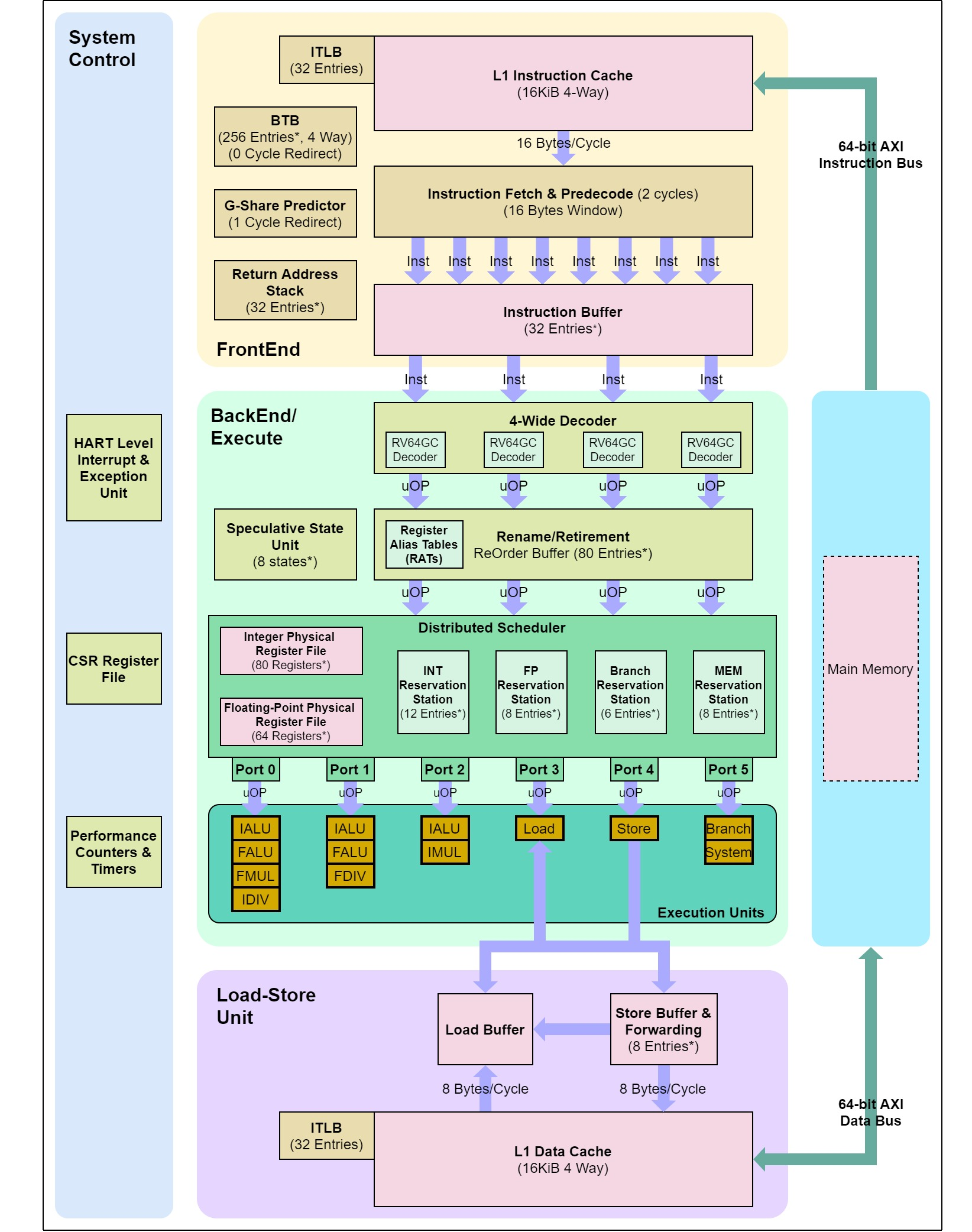
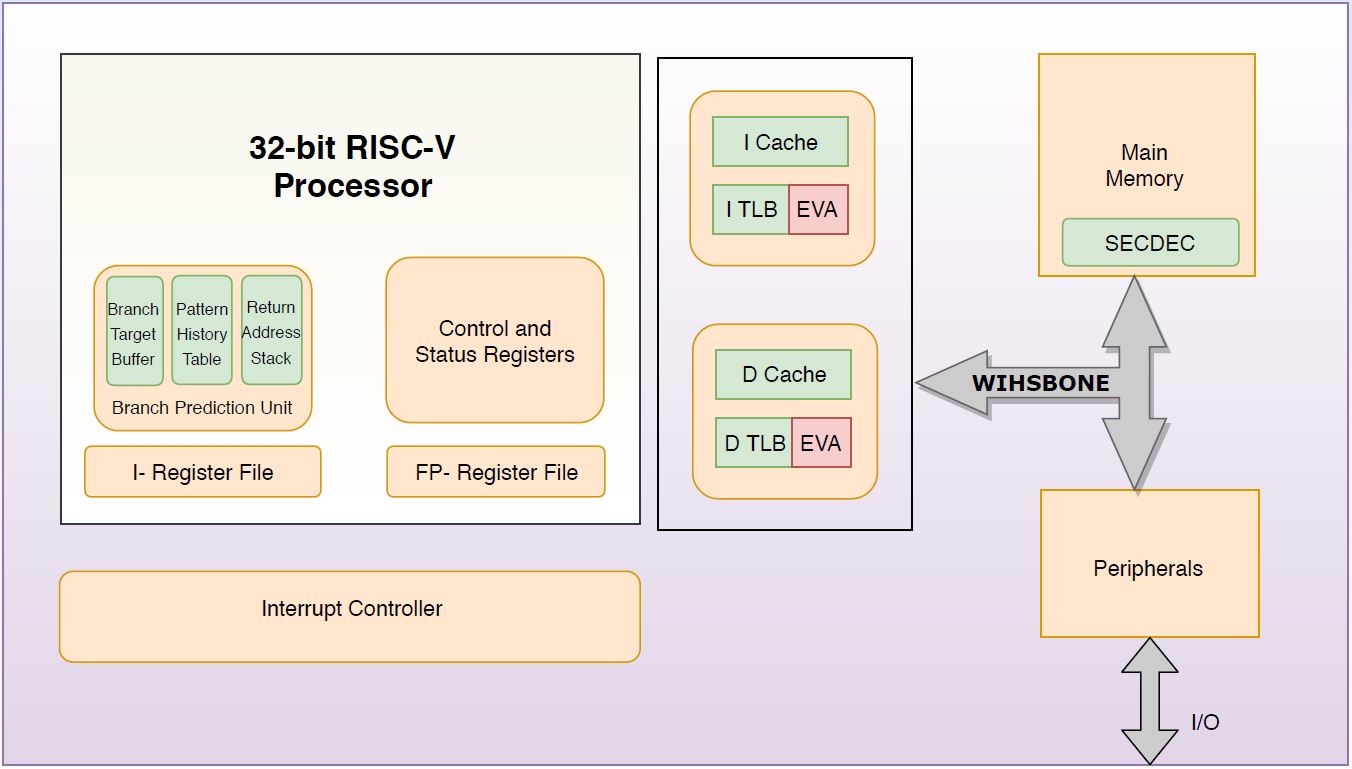
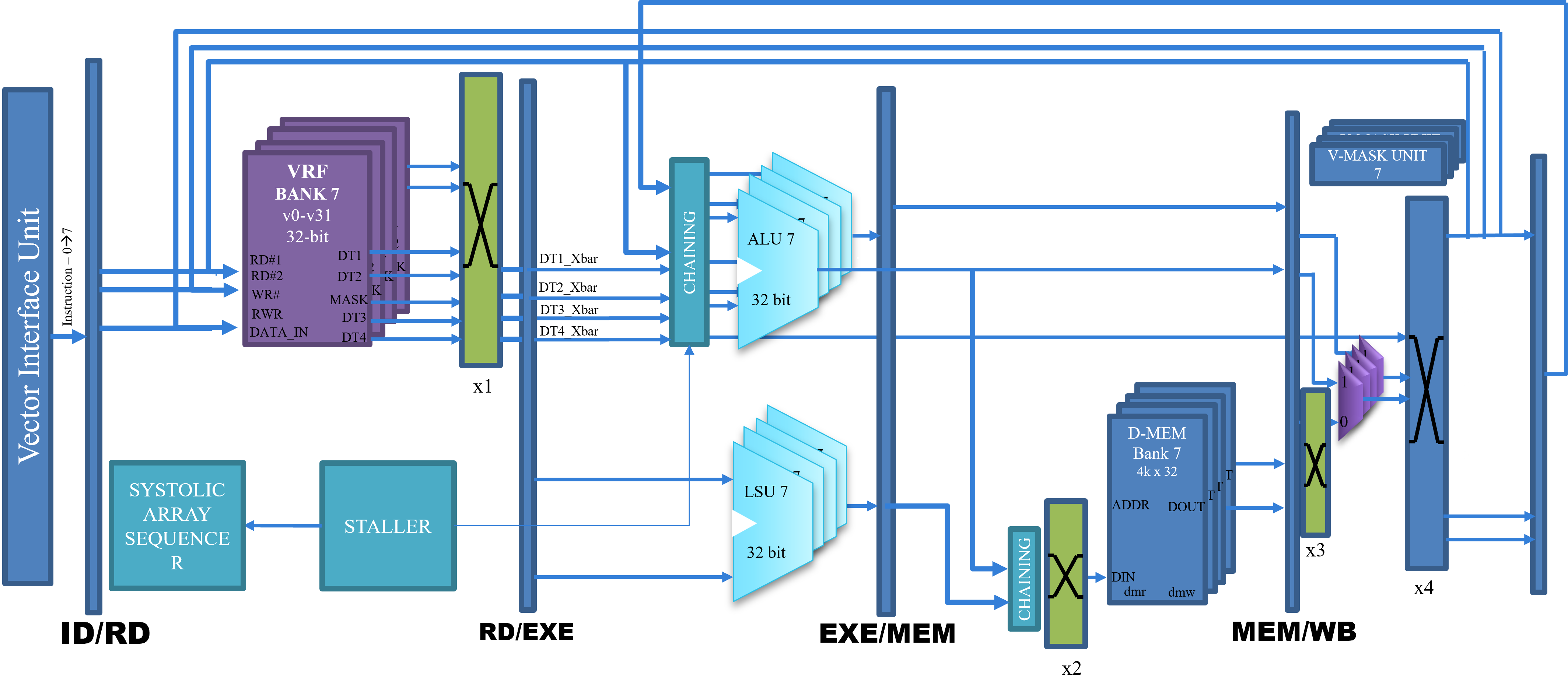
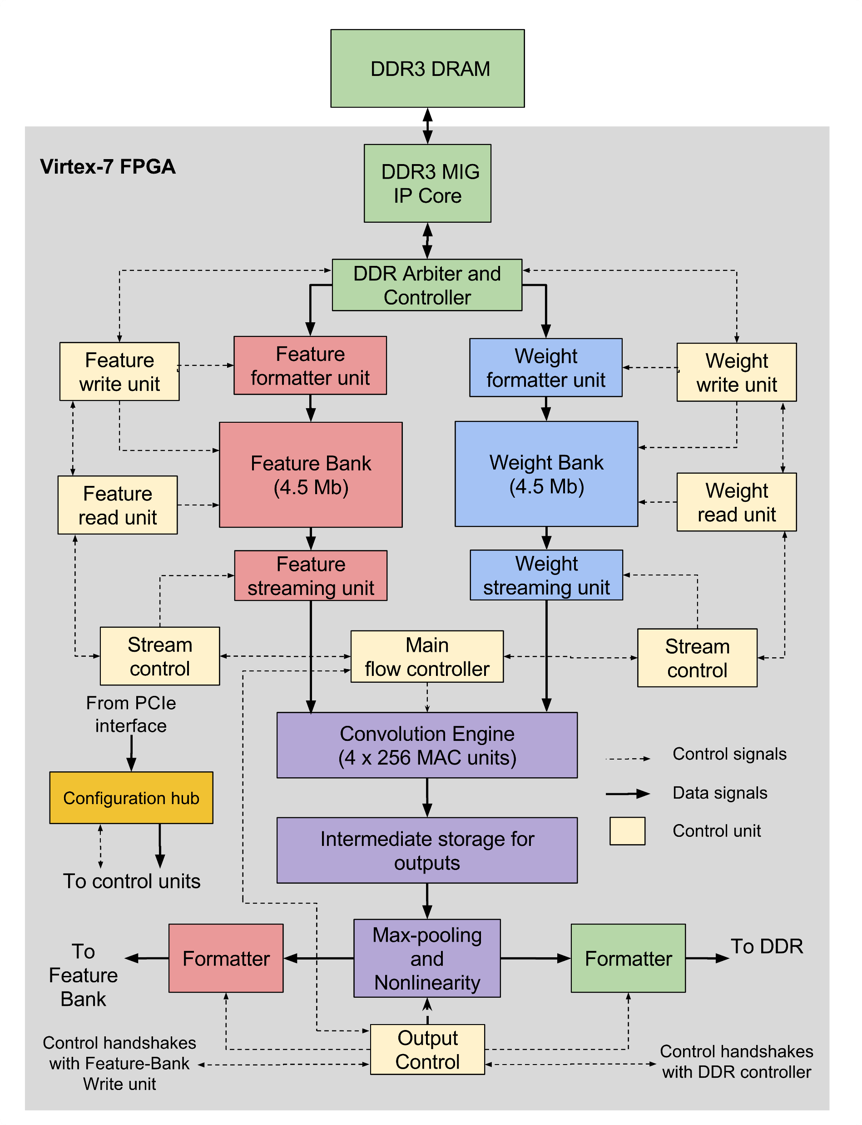
Address:
Room No.: 221
First Floor
Department of Electronic Systems Engineering
Division of EECS
Indian Institute of Science
Bangalore 560012, INDIA

Room No.: 221
First Floor
Department of Electronic Systems Engineering
Division of EECS
Indian Institute of Science
Bangalore 560012, INDIA