Introduction
The future of the micro controller mostly depends on the machine learning in embedded system. The cloud computing has intelligence of the machine learning but it is not useful for the real time applications. The intelligence could be shifted to the edge devices partially still network will suffer problems like latency, security, power and bandwidth costly communication. The next level is to transfer intelligence to the end device which has sparse resources. The implementation of the machine learning and DSP algorithms efficiently in embedded system without loss of accuracy. This paper will show the hardware and software solutions to overcome the challenges faced when porting the machine learning algorithms.
Machine Learning
The machine learning computation is possible due to the machine has become powerful due to VLSI technology. Machine learning has been useful in IOT and embedded applications. Machine learning algorithms are useful in systems deployed in the dynamic environment, handling large data which is increasing day by day due to increase in number of IOT devices, data traffic monitoring and useful in security of the data. Machine learning algorithms like CNN, RNN, linear regression are useful in applications like image classification, speech recognition and natural language processing.
Challenges
Challenges in implementation of ML and DSP algorithms on embedded system are as follows.
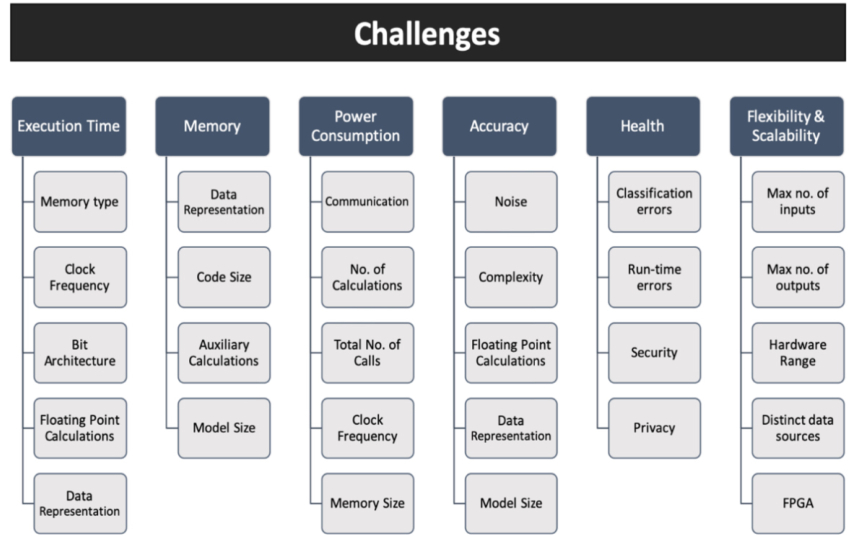
The above image shows the challenges of execution time(performance), memory, power consumption, accuracy, health , reliability and scalability.
The trade off also present between some factors like performance and power consumption depending on the clock frequency.
Hardware solutions
Machine learning and DSP algorithms has some common operations that can have high performance like MAC operation having efficient MAC engine. The some of the hardware solutions mentioned below :
1. ASIC + Microcontroller
To increase the performance of the system , application specific hardware and microcontroller can be used together.
2. SOC implementation
The implementation of hardware accelerators, processor on FPGA device.
3. Technological Developments
1. 2D GPU (Graphical Processor Unit)
2. Helium Technology
3. DAM support 4.Hardware accelerators : TCM, Security IPs
5.Neural Processing Unit, FPU(floating point unit), DSP unit
6.Faster memories : SSD
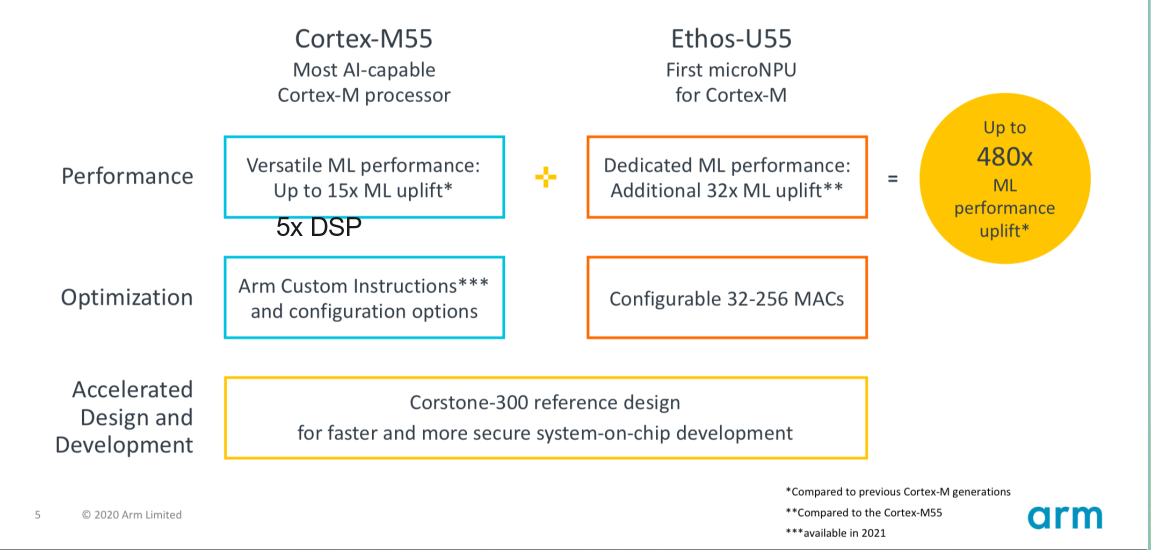
The above mentioned are some of the hardware solutions to minimise the challenges of implementation. The hardware solutions by ARM are recently launched ARM CORTEX- M55 processor and Neural processing unit Ethos-U55. The overall performance of these solution are shown below
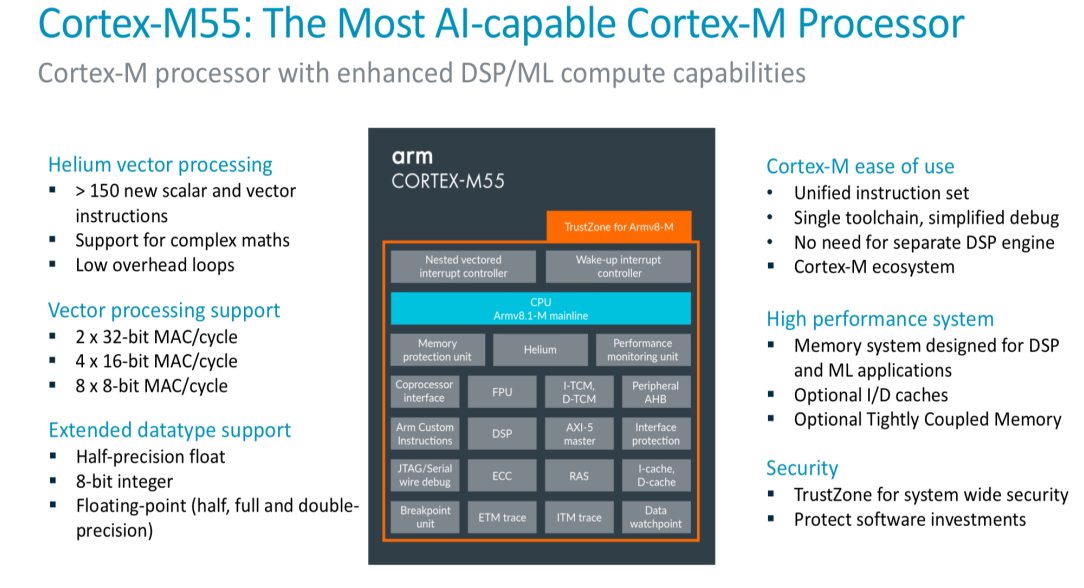
CORTEX-M55
ARM developed AI capable processor CORTEX-M55 recently with some architecture design considering the AI and DSP applications at end devices. The following image shows the features included in the CORTEX-M55.
NPU: Ethos-U55
ARM developed neural processing unit(NPU) which is high performance and configurable hardware of the machine learning operators that are present in most of the ML algorithms. The following image shows the features included in this NPU.

The flow of the ML implementation using CORTEX-M55 and Ethos-U55 at end devices shown below.
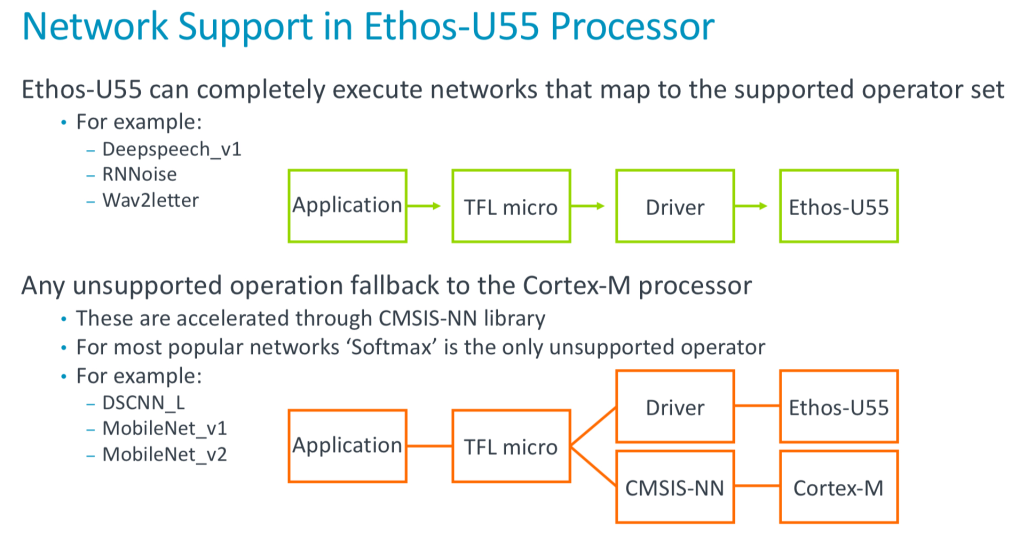
Software solution : CMSIS-NN
There many software solution like Tensorflow Lite for ML, CMSIS-NN library,unified software development of Embedded code, DSP code and Neural network model. This paper will discuss the architecture of the CMSIS-NN for ML.
CMSIS-NN Architecture
CMSIS-NN is a collection of efficient neural network kernels developed to maximise the performance and minimise the memory footprint of neural network on ARM Cortex-M processor cores targeted for intelligent IoT end and edge devices.
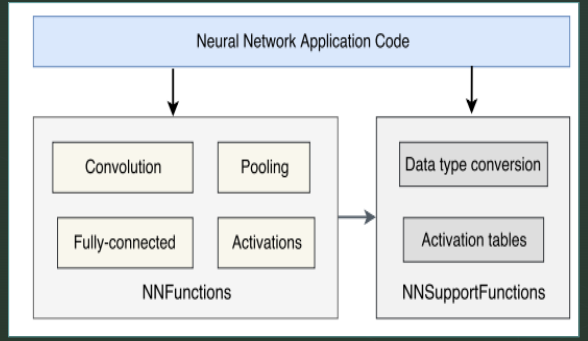
The above image show the architecture of the CMSIS-NN. The optimisations implemented in CMSIS-NN for improving the performance and reducing memory footprint are as stated below :
1. Fixed Point Quantisation
This will avoid costly floating-point computation and reduces memory usage. The accuracy will affect little but it can manageable in machine learning applications. 2. Support Functions
3. Matrix Multiplication
supporting SIMD instructions, MAC instructions(e.g.SMLAD).
4.Convolution
5.Pooling
Pooling layers are used to reduce the features dimensions and thus parameters and computation in the network.
6.Activation functions
The above all implemented in efficient way such that, algorithm implemented using CMSIS-NN shows the higher performance , low power and low resource requirement.
Conclusion
This paper referred to both hardware and software solutions possibles for ML end computing. Hardware solutions of Ethos U55 and Cortex M55 by ARM are discussed above.
References
1.Machine Learning in Resource-Scarce Embedded Systems, FPGAs, and End-Devices: A Survey by Sérgio Branco , André G. Ferreira and Jorge Cabral
2. Macine Learning for Embedded System: Case Study – 2015, KAran Zita Haigh, Allan M.Mackay, Michael R.Cook, Li G.Liin, Raytheon BBN technologies
3. CMSIS-NN: Efficient Neural network kernels for ARM Cortex-M CPUs – 2018, Liangzhen Lai Naveen Suda Vikas Chandra
4. Webinar by ARM https://www.brighttalk.com/webcast/17792/391867
5. CMSIS NN Library https://github.com/ARM-software/CMSIS_5
Recent Comments