INTRODUCTION
Machine learning algorithms are becoming increasingly popular now a days. They have many interesting applications like Face Detection, Image Classification, Speech Recognition, Self-driving cars etc. Typically implementing these algorithms requires lot of computing power involving a lot of floating point multiplications. So naturally one asks whether these type of algorithms can be implemented on Embedded platform in an efficient way. In this project we try to answer this question.
DESCRIPTION
We have taken up the task of classifying traffic signs using a Convolution Neural Network(CNN). CNN’s are very similar to ordinary Neural Networks except that they are made up of neurons with sharable weights. In both the architectures, we have learnable weights and biases. Each neuron receives some inputs, performs a dot product and optionally follows it with a non-linearity. CNN networks use differentiable score function from the raw image pixels on one end to class scores at the other with some loss function (e.g. Softmax).
In CNN architectures, we make an explicit assumption that the inputs are images, which allows us to implement the forward function more efficiently by vastly reducing the number of parameters in the network.
For ex., for a 32x32x3 image, ‘a single’ fully-connected neuron in a first hidden layer of a regular Neural Network would have 32*32*3 = 3072 weights (excluding biases). Thus, this fully-connected structure does not scale to larger images with higher number of hidden layers. On the contrary, CNN uses 5x5x3= 125 weights for ‘a single filter’, which does not scale up in number with increase in the input volume size.
The dataset required for training is obtained from here[1]. We have used 11760 images from 5 classes to train the network.
DEMO SETUP
- The input image was sent via UART to the microcontroller. The pixel values of the image were sent iteratively from Octave.
- As soon as all the pixels are received, the program starts CNN computation and displays the class label in the serial port hyperterminal, and displays the predicted image on Nokia LCD display.
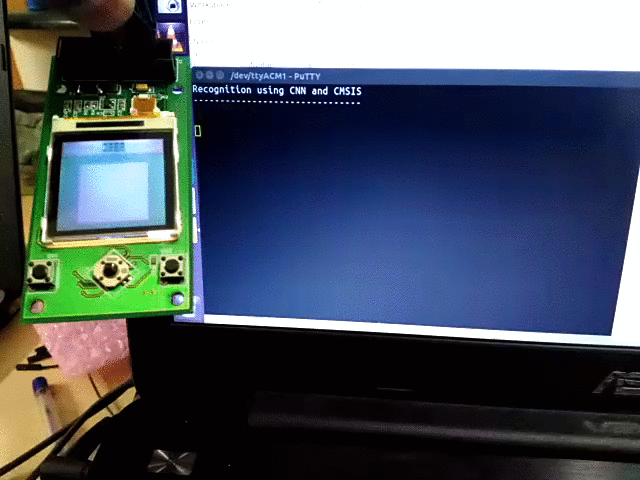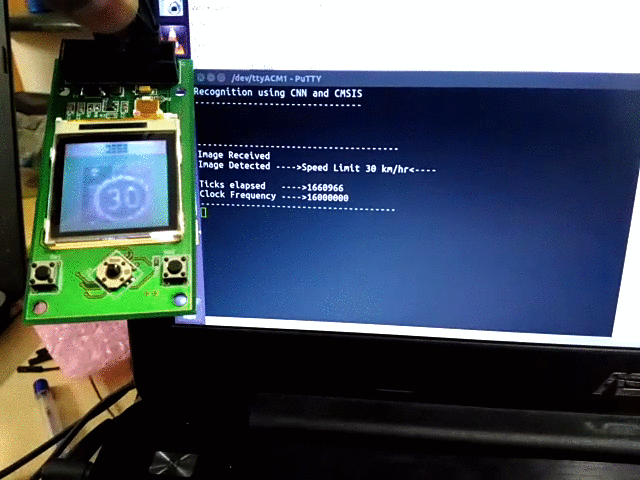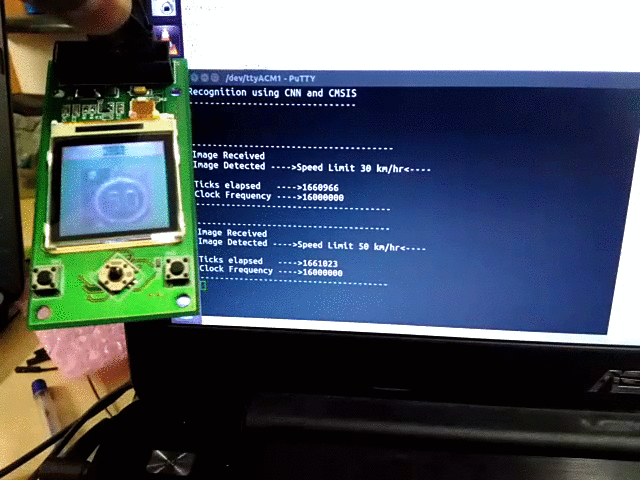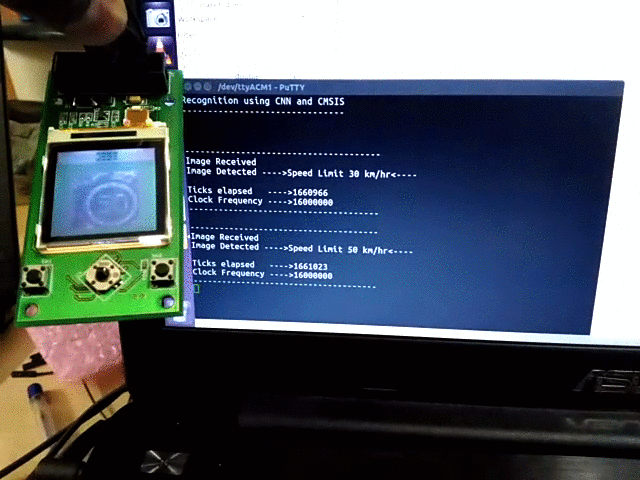
The complete source code for the project is available at https://github.com/djvishnu92/cmsisCNN.
NEURAL NETWORK ARCHITECTURE
General architectures in CNN’s use:
- Convolution layer
- Max pool layer
- Flatten layer
- Fully connected layer
Convolution layer and Fully Connected layer are optionally followed by a activation function to learn non-linear classification problems.
TRAINING
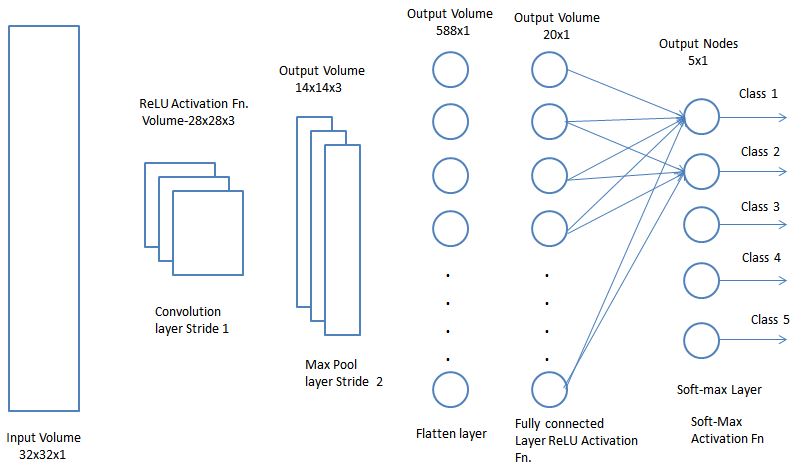
We have used machine learning library ‘keras’ in python to train the network and weights are obtained after training. Cross validation has been used for model validation and assessment. The data set obtained is split in the ration of 90:10 (training data: validation data) for this purpose. Based on the validation accuracies obtained, the network’s hyper parameters have been fixed. For the purpose of classification, we have decided using
- 5x5x3 convolutional layer (Stride 1) with ReLU activation function,
- 2×2 Max pool layer (Stride2)
- Flatten layer two convert the output volume of the max pool layer into a single dimension
- The output volume of the flatten layer (588×1) is passed through a softmax layer with ReLU activation function.
- The output volume of the softmax layer (20×1) is passed through softmax activation function to obtain the class label.
In the five class classification problem, we have used 1 of K representation for deciding the class labels. i.e. If the test image belongs to class 2, the output class label vector will be (0,1,0,0,0). Softmax activation function finds the maximum of the predicted class scores and normalizes it to values between 0 and 1.
CHALLENGES
There are 5*5*3 weights and 5 biases for the filters, 588*20 weights and 20 biases for the fully connected layer and 20*5 weights and 5 biases for the output layer.
So, in total there are 11,935 weights and 30 biases for the network despite of sharing weights. We have a total of 5x5x32x32x3 + 588×20 + 20×5 = 88,660 floating point multiplications and a total of 1023×3 + 587×20 + 19×5 = 14,904 additions for one forward propagation, in our current architecture which is very high and consumes lot of computing power and time.
Hence in this project, we intend to compare the computation time on a embedded platform with and without using the inbuilt DSP resources like Multiply and Accumulate(MAC) and Floating Point Unit(FPU).
USING ARM CMSIS DSP LIBRARY
The above CNN algorithm involves matrix multiplications of very high order. Performing such operations using normal C code requires a lot of clock cycles. Alternatively, one can use CMSIS library to perform computations faster. CMSIS is a vendor independent hardware abstraction layer for the Cortex M processor and defines generic tool interfaces. Click here (https://www.arm.com/products/processors/cortex-m/cortex-microcontroller-software-interface-standard.php) to learn more about CMSIS.
CMSIS-DSP library is a suite of common signal processing and mathematical functions that have been optimized for the Cortex M4 processor. The library has separate functions for operating on 8-bit integers, 16-bit integers, 32-bit integers, and 32-bit floating point values. The Cortex-M4 version of the library uses instruction set extensions to boost execution speed by a factor of two for fixed-point and a factor of ten for floating-point DSP algorithms. The standardization of the optimized CMSIS-DSP library reduces software development costs and provides the ARM ecosystem with a foundation for filter design utilities and other high-level DSP development tools.[2]
Click here (https://github.com/ARM-software/CMSIS) to download the CMSIS-DSP library. The documentation is provided at CMSIS/Documentation/General/html/index.html after extracting the zip file. Follow the instructions given in CMSIS file (http://www.ti.com/lit/an/spma041g/spma041g.pdf), to setup/compile the CMSIS-DSP library in Code Composer Studio for use in TM4C microcontrollers.
For the above architecture, CNN algorithm uses
- 2D convolution of the input image with each of the 3 filters (image(32 x32) * filter (5×5) each)
- one matrix multiplication at the output of flatten layer (1×588 and 588×20)
- one matrix multiplication at the output of the fully connected layer (1×20 and 20×5)
The above operations were performed with
- normal C code using loops
- arm_mat_mult_f32 , a CMSIS-DSP API for 32-bit floating point matrix multiplication.
RESULTS
The number of CPU clock cycles taken for computation of one image is compared in both cases i.e. using normal C loops and CMSIS DSP APIs.
The same set of images were given as input to the system, and the following observations were made
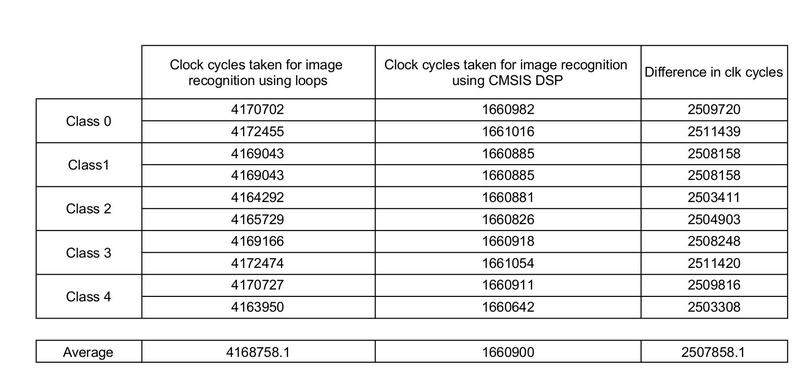
It was observed that, using the CMSIS API took only almost one-third the clock cycles taken by loops, for the classification of the same input image.
On an average, using the CMSIS-DSP library saves about 2.5 million clock cycles than when implemented using loops. For a 16 Mhz clock frequency, the CMSIS-DSP library saves approximately 150 ms. The difference is because the CMSIS DSP library uses FPU in the cortex M4 microcontroller.
As explained earlier we have 1lakh floating point operations for one computation. Using DSP library saves about 25 CPU clock cycles per floating point operation. The savings are huge because our computational requirements are huge. So when we have huge computations involved on embedded platforms opting DSP libraries proves to be much efficient than using normal C loops.
REFERENCES
- Convoltional Neural Networks – http://cs231n.github.io/convolutional-networks/
- CMSIS – https://github.com/ARM-software/CMSIS
- CMSIS Documentation – https://www.keil.com/pack/doc/CMSIS/DSP/html/index.html
- ARM Introduces CMSIS-DSP – https://www.arm.com/about/newsroom/arm-extends-software-interface-standard-with-dsp-library.php
TEAM MEMBERS
- DESAI JAGANNATH VISHNUTEJA
- JAYANTH K
- SUDDPALLI KRISHNA CHAITANYA
Recent Comments