This work discuss about various low power design aspects of the microprocessor.
Design layers for low power
- Architectural designs
- Clustered architecture
- Simultaneous multi-threading
- Dynamic power management techniques
- Clock gating
- Instruction cache throttling
- Dynamic voltage and frequency scaling
- Software low power techniques
- Compiler optimization
- Code morphing
- Low power task scheduling
Architectural designs
Clustered architecture
- The instruction issue width is the maximum number of instructions that can be issued in one cycle.Increasing the issue width increases not only the complexity of the instruction queue (Issue window) but also the number of read/write ports in register files, the number of functional units, and the result bus width.With clustering techniques, the instruction issue width is divided into several small clusters.
- The microarchitecture clustering techniques are used for lowering the power consumption in microprocessor architectures.The microprocessor is divided into multiple clusters.The register file, issue window, and functional units are distributed across multiple clusters and each cluster is assigned a subset of the architectural registers.
- The power consumption reduces significantly by resolving the inter-cluster dependency.This is done by the forwarding logic.
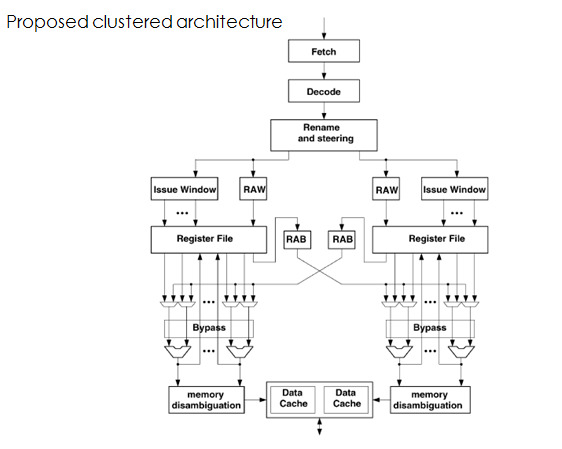
- The block RAB is the forwarding logic which transfers data from one cluster to the other and resolves the dependencies between them.The register file contains dynamic subset of physical registers.The execution units consist of dynamic logic circuitry for various integer and floating point arithmetic operations required to support the instruction set of the microprocesor.
- The memory disambiguation unit executes the memory access instructions in out-of-program order in a high performance out-of-order execution microprocessor. The data cache is interleaved which require one address to be calculated from which individual fields may be accessed.
Simultaneous multi-threading
- Simultaneous multi-threaded(SMT) processor utilizes up to 22% less energy per instruction than a single-threaded architecture.An SMT processor with small execution bandwidth achieves comparable performance at low power.An SMT processor utilizes instruction level parallelism (ILP) and thread level parallelism (TLP) interchangeably. ILP is achieved by executing multiple instructions from a single program in a single cycle. TLP is achieved by executing multiple threads which share all the processor resources every cycle.
- By running multiple threads less power is wasted on under-utilized execution resources. Through the thread selection mechanism the power optimization is achieved.The heuristic used to select which threads fetch can have large impact on performance.
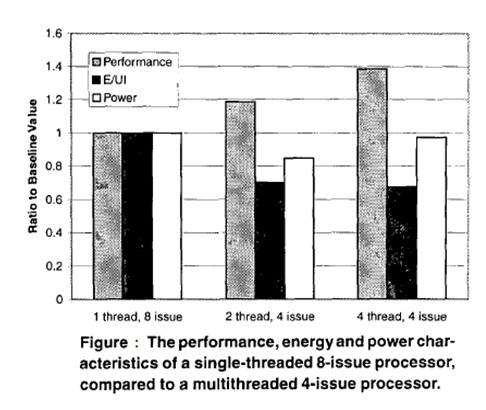
- The results show that the 4 issue muti-threaded processor provides comparable and greater performance than the 8 issue single threaded processor.When multi-theading is enabled the overall efficiency of the processor is improved significantly.The power comsumption also drops.There is a slight increase in the power when the level of multi-threading increases from 2 to 4 threads.
- It is found that by imultaneous multi-threading,the estimated sizes of the fetch unit and the register renamer were reduced by 50%,the estimated size of the issue queues were reduced by 25% and the maximum number of instructions that are released from the instruction queues per cycle became half.
Dynamic power management techniques
Clock gating
- The clock distribution network typically consumes a large percentage of the processor power.In clock gating, the clocks are turned off to idle portions of the processor.The clock gating signals are used to cut-off the clock. The clock gating signals must be valid halfway the clock cycle. Fine calibration of clock distribution network is required.
- Methods for gating the processor execution units
- Opcode based method
- Value based method
-
- In opcode based method,the information about which execution units are going to be used in the next cycle which is known after the decoding stage is used to generate clock gating signals for unused units.
- Even though the processor data path is designed for 32 or 64 bit in most of the real applications as many as 50% operations would require only 16 bit or less. So to avoid unnecessary computations on zero values, gating signals are used to activate the function unit for different bit widths.This is value based method. At run time, based on the operand value appropriate width of the function unit is activated.
Instruction cache throttling
- This mechanism is provided to effectively lower the instruction execution rate without the complexity and overhead of dynamic clock control.The Instruction Cache Throttling mechanism simply throttles the instruction forwarding from the instruction cache to the instruction buffer.
- In the PowerPC, the instruction forwarding rates from the instruction cache to the instruction buffer can be controlled by setting the rate control register. Therefore, the idle time of the CPU increases and the overall temperature decreases.
- To lower the instruction forwarding rate, a non-zero value is written into the Instruction Cache Throttling Control Special Register(ICTC_SPR).The system software can control the instruction forwarding rate through privileged accesses to the ICTC-SPR.
Dynamic voltage and frequency scaling
- The computational requirements for a task can be intensive,low speed or Idle.Low speed long latency task requires a fraction of the processor throughput to run.Power can be saved by reducing clock frequency during non-compute intensive activity.
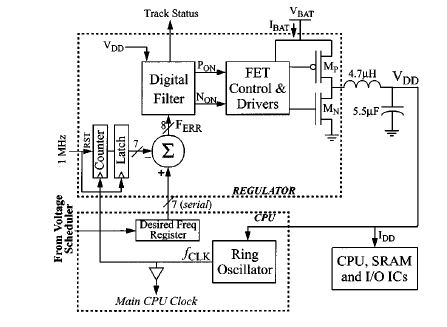
- The ring oscillator provides translation from supply voltage to operating frequency.The output voltage drives the ring oscillator whose output clock signal can be readily converted to a digitally measured clock frequency.The operating system controls regulation loop by giving the difference between desired frequency and measured frequency as feedback.The hardware loop determine the minimum required supply voltage to meet this desired frequency.
- Voltage scheduler is used in DVS system.It controls the processor speed by writing the desired clock frequency to a system control register. The register’s value is used by the regulation loop to adjust the CPU clock frequency and regulated voltage.
- In this figure, the ring oscillator on the CPU chip outputs a clock signal whose frequency is a function of the supply voltage VDD. The clock signal is sent to the regulator chip and drives a counter which is latched and reset to 1 MHZ intervals.It quantize the clock frequency into a 7 bit word.This value is subtracted from the desired frequency as set by the operating system, to create an 8-bit frequency error.This error given to loop filter .The loop filter circuit implements a hybrid pulse-width/pulse-frequency modulation algorithm which generates signals to enable the power FETs. The buck converter circuit and LC tank circuit down convert VBAT to the regulated voltage VDD which is fed back to the CPU and forming a close loop.
Software low power techniques
Compiler optimization
- The optimization levels of gcc compiler are:-
- -O0 :- No optimizations performed
- -O1 :- Many local optimizations and global optimizations are performed. These include common sub-expression elimination, combining instruction through substitution (copy propagation), dead-store elimination, loop strength reduction and minimal scheduling.
- -O2 :- Nearly all supported optimizations that do not involve a space-speed tradeoff are performed. Loop unrolling and function inlining are not done, for example. This level also includes an aggressive instruction scheduling pass.
- -O3 :- This turns on everything that -o2 does, along with also inlining of procedures.
- The influence of Standard Optimizations on Power
- The instructions per cycle reduces in -O1 codes but increases in –O2 and -O3 codes.The level -O1 reduces the number of instructions drastically as compared to -O0 because it invokes optimizations such as common subexpression elimination, an optimization used to eliminate redundant computations in the program.
- Most optimizations that increase instructions per cycle such as instruction scheduling, loop unrolling etc are included in –O2 and -O3 levels.Power dissipation is directly proportional to instructions per cycle. Hence the optimizations that increase instructions per cycle will increase power consumption.Hence –O2,-O3 optimizations are good for performance but will increase power consumption. So –O1 optimization is preferred for low power consumption.
Code Morphing
- The Crusoe processor solutions consist of a hardware engine logically surrounded by a software layer. The engine is a very long instruction word (VLIW) CPU capable of executing up to four operations in each clock cycle.The surrounding software layer gives x86 programs the impression that they are running on x86 hardware.The software layer is called Code Morphing software because it dynamically “morphs” x86 instructions into VLIW instructions.
- The Code Morphing software simplifies chip hardware. This is a program that compiles instructions for one instruction set architecture (ISA) into instructions for another ISA. The power savings come from replacing large numbers of transistors with software.
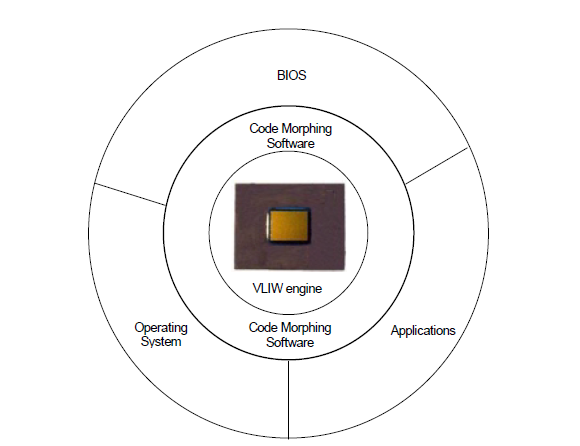
- Figure shows the relationship between x86 code, the Code Morphing software, and a Crusoe processor.The Code Morphing software insulates x86 programs including a PC’s BIOS and operating system from the hardware engine’s native instruction set, that native instruction set can be changed arbitrarily without affecting any x86 software at all.
Low power task scheduling
- Dynamic power management shuts down unused devices to save power. When serving requests (busy), a device must be in a high-power working state.When a device is not serving any requests (idle), it can be shut down and put into a sleeping state to save power.Power state changes are decided by a power manager .It wakes up a device to serve requests and shuts it down to save power. State changes take time and energy so a device should be shut down only if it can sleep long enough to compensate the performance and energy overhead.
- The lengths of idle periods can be adjusted by ordering task execution.This saves power and it has another benefit, the clustered idle periods reduces shutdowns hence reduces state transition delays.
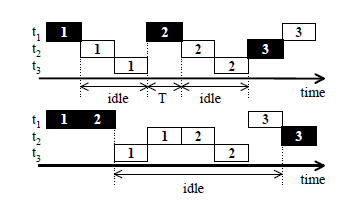
- In this figure a block indicates that a task is running. If the task generates requests, the block is filled and an unfilled block indicates that the task does not generate requests.Figure shows two schedules of three independent tasks. The second schedule reorders execution to make long, continuous idle period. Compared to second schedule the processor will shut down twice in the first schedule.So wasting energy in the first schedule is twice than the second schedule.Hence second schedule is better than first schedule in terms of low power consumption.
References
- Low Power Microprocessor Design for Embedded Systems, Seong-Won Lee, Neungsoo Park and Jean-Luc Gaudiot
- Simultaneous multi-threading :- Lo, J., Eggers, S., Emer, J., Levy, H., Stamm, R., Tullsen, D.: Converting Thread-Level Parallelism to Instruction-Level Parallelism via Simultaneous Multithreading.ACM Transactions on Computer Systems (1997) 322–354
- Clock gating :- Brennan, J., Dean, A., Kenyon, S., Ventrone, S.: Low Power Methodology and Design Techniques for Processor Design. In: Proc. the 1998 Int’l Symp. Low-Power Electronics and Design. (1998) 268–273
- Clustered architecure :- Zyuban, V., Kogge, P.: Inherently Lower-Power High-Performance Superscalar Architectures. IEEE Transactions on Computers 50 (2001) 268–285
- Instruction Cache Throttling :- Sanchez, H., Kuttanna, B., Olson, T., Alexander, M., Gerosa, G., Philip, R., Alvarez,J.: Thermal Management System for High Performance PowerPC Microprocessors.In: Proc. the 42nd IEEE Int’l Computer Conference, Motorola, Inc.and Apple Computer Corporation,USA (1997) 325–330
- Dynamic voltage and frequency scaling :- Burd, T., Pering, T., Stratakos, A., Brodersen, R.: A Dynamic Voltage Scaled Microprocessor System. IEEE Journal of Solid-State Circuits (2000) 1571–1580
- Compiler optimization :- Valluri, M., John, L.: Is Compiling for Performance == Compiling for Power? In:Proc. the 5th Annual Workshop on Interaction between Compilers and Computer Architectures (INTERACT-5). (2001)
- Code morphing :- Klaiber, A.: The Technology Behind Crusoe Processors. (Transmeta Corporation)
- Low power task scheduling :- Lu, Y., Benini, L., Micheli, G.D.: Low-Power Task Scheduling for Multiple Devices.In: Proc. 8th Int’l Workshop on Hardware/Software Codesign. (2000) 39–43
Recent Comments