Problem Statement
Aim: To recognise a single upper case character saved as an image on PC and display the result
Demo
The image in PC is sent to TIVA microcontroller.
The image being recognized is displayed on NOKIA LCD display.
The predicted character is displayed on PC terminal.
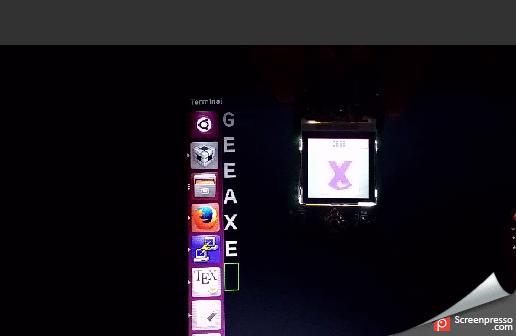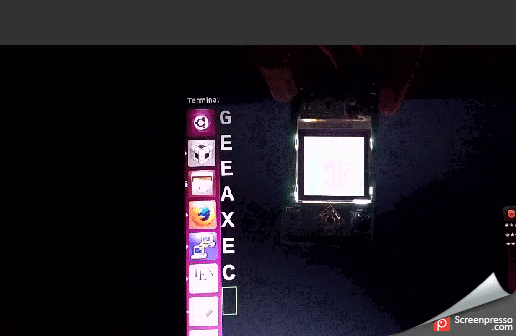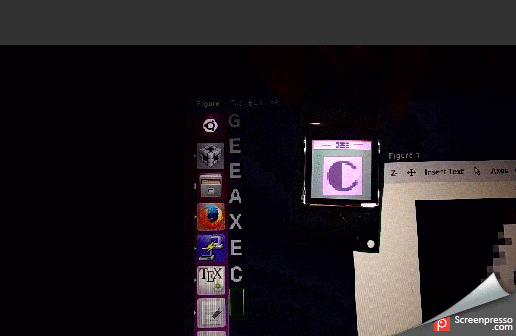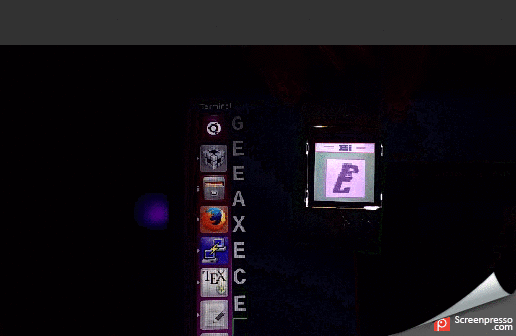
Data transfer
Image is saved as 8 bit 28×28 grayscale image in PC. It is sent to TIVA microcontroller through UART file transfer. The image write starts with writing a character ‘s’ through UART followed by 784 pixel values in column major format. TIVA accepts the image through UART interrupt service routine. Once the image transfer is complete, it is displayed on NOKIA LCD. The prediction algorithm starts as soon as the image is displayed. Once the prediction is completed, the predicted character displayed on PC terminal. To read back the image that is currently loaded, a character ‘r’ is sent to UART. The microcontroller will respond with 784 pixel values through UART which can be read.
Learning Objectives
- Interfacing NOKIA LCD display
- Neural Network training and prediction
- UART file transfer
- SPI bit banging
Hardware connections
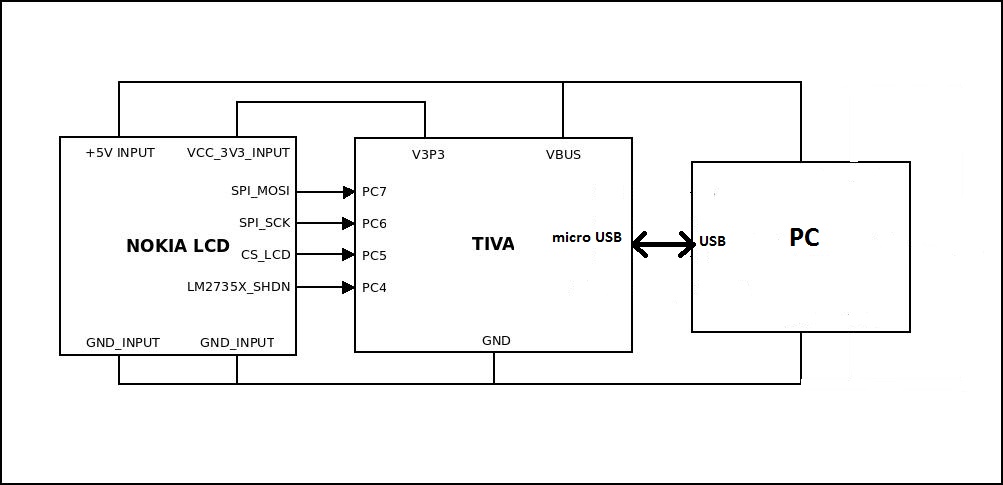
Hardware connections

Hardware connections
NOKIA LCD Interfacing
NOKIA 6100 LCD interfacing is through SPI implemented by bit banging. Each transfer of command/data contains 9 bytes with MSB sent first through MOSI pin. A logic high MSB indicates command and logic low MSB indicates data. The rest of the bits determine the actual command/data. The data or command is latched on each high to low edge of clock. Chip select needs to be made low before each transaction.
Training and prediction
Multilayer Perception algorithm is used to train the Neural Network. Sigmoid neuron is the basic building block of MLP . Each neuron in MLP takes several inputs (x1,x2, ..) and produces a single output. Each ith input is multiplied by any value between 0 and 1 and these are called weights. Thus each ith input has weights, wi,1, wi,2, …wi,N (where N is the number of Hidder layer) and bias, b1 ,b2, ……. bN (where N is the number of Hidder layer dimension or Output layer dimension) . Its output is σ(w.x+b), where σ is the sigmoid function.
Neural network used for character recognition contains 3 layers – Input layer containing 784 (28×28) input neurons, hidden layer containing 30 neurons and output layer with 26 output neurons.
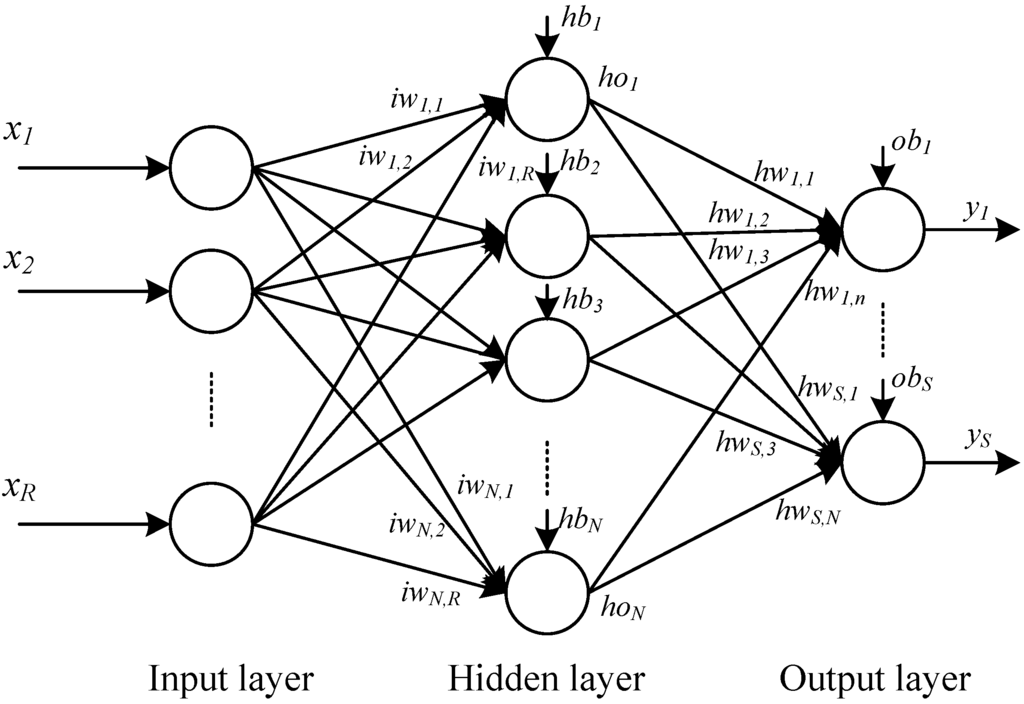
Neural network for upper case character recognition
Training of the neural network is done with 74000 images of handwritten digits fetched from database[1]. – http://yann.lecun.com/exdb/mnist/. Goal of the training process is to minimize the cost function which is the average norm of the error between predicted value and target value. Cost function is minimized using stochastic gradient descent algorithm by updating the weights using back propagation after every image prediction. Gradient descent algorithm works on the principle that gradient of a multi dimensional function represents the direction of maximum change in the function with its magnitude being the maximum rate of change. This ensures that each iteration will result in reduction of error provided the step taken is less than the magnitude of the error. At the same time step taken should be high enough for faster convergence of the training. There are 784*30 weights for the hidden layer and 30*26 weights for the output layer.
Code used for Training: https://github.com/gitofchetan/Alphabet-Recognition/tree/master/Train_code
Hidden weights w1i,1, w1i,2, …w1i,30 and Bias b11 ,b12, ……. b130 are found for input data. Also hidden weights w2i,1, w2i,2, …w2i,26 and Bias b21 ,b22, ……. b226 are found for output data. These weights are ported to TIVA microcontroller and is used to find the output of the neural network. Digit is predicted by the micro-controller from 784 pixel values received from UART and the fetched weights. Output vector is found using the following equation
Input to the output layer, [hiddenOutput]30×1= sigmoid([hiddenWeights]30×784 * [inputVector]784×1 +[Bias1]30×1)
Output of the output layer, [outputVector]26×1= sigmoid([outputWeights]26×30 *[hiddenOutput]30×1 +[Bias2]26×1)
Index of the output neuron which has the highest output value is the predicted character.
Code used for Prediction in TIVA: https://github.com/gitofchetan/Alphabet-Recognition/tree/master/Source_code
Training and prediction algorithm for digit recognition explained in http://neuralnetworksanddeeplearning.com/
Components Used
- TIVA microcontroller
- NOKIA LCD Display
Softwares used
- Code Composer Studio
- TivaWare Peripheral Driver Library
- gcc
- Octave
References
- NOKIA LCD Display driver
- NOKIA LCD Board schematic
- MNIST digit database – http://yann.lecun.com/exdb/mnist/
- Neural network notes – http://neuralnetworksanddeeplearning.com/
Source code
All the source code can be found at https://github.com/gitofchetan/Alphabet-Recognition
Future scope
- Training implementation on TIVA
- Image read from SD card
- Multiple character and Special Character recognition
Team Members
- Chetan Achari
- Piyush Birla
Recent Comments