ABSTRACT
This course project explores software–hardware co-design for accelerated packet processing on the Zynq UltraScale+ ZCU102 platform. Ubuntu Linux is installed and used to evaluate AF-XDP–based fast packet processing in user space. The project further investigates programmable logic configuration from Ubuntu using dynamic overlays, followed by AXI interface validation through a simple PL-based design. A PS–PL co-design framework is then developed to offload SHA-3 computation to the FPGA fabric, and the performance is compared against software execution on the Processing System. The results demonstrate clear acceleration benefits and outline a scalable approach for Ubuntu-based FPGA-enabled networking.
I.INTRODUCTION
Modern communication networks are increasingly required to operate at very high data rates, typically in the range of 10 Gbps to 100 Gbps, to support cloud computing, data centers, edge computing, and real-time services. At these link speeds, packet processing requirements scale to several million packets per second (Mpps). For instance, a 10 Gbps Ethernet link operating with minimum-sized packets requires processing approximately 14.8 Mpps, corresponding to a per-packet budget of only 67.5 ns. At 100 Gbps, this requirement increases to nearly 148 Mpps, leaving less than 7 ns available per packet. Such stringent timing constraints make conventional software-based packet processing increasingly challenging.
Traditional operating system networking stacks, including those in Linux, are designed for general-purpose workloads and prioritize flexibility and portability. Packet traversal through the kernel networking stack typically involves multiple protocol layers, interrupt-driven packet reception, context switches between kernel and user space, and several memory copies. While these mechanisms simplify application development, they introduce significant latency and pro-cessing overhead, limiting achievable throughput and increasing jitter. As packet rates increase, CPU cores quickly become saturated, making it difficult to sustain line-rate packet processing using standard socket-based approaches.
Recent advances in kernel-bypass and fast-path networking, such as extended Berkeley Packet Filter (eBPF), Express Data Path (XDP), and AF XDP sockets, have significantly im-proved packet processing performance in Linux systems. XDP enables packet processing at the earliest point in the network driver, while AF XDP allows zero-copy delivery of packets directly to user space. These mechanisms reduce overhead by avoiding parts of the traditional networking stack and minimizing data copies. However, even with these optimizations, packet processing remains fundamentally CPU-bound, especially for workloads involving crypto-graphic operations, hashing, deep packet inspection, or other compute-intensive per-packet tasks.
Field Programmable Gate Arrays (FPGAs) provide an attractive platform for accelerating such workloads. FPGAs offer massive parallelism, deterministic execution, and predictable latency, making them well suited for high-throughput, low-latency packet processing. Unlike CPUs, which execute instructions sequentially and are subject to operating system scheduling, FPGA-based accelerators can be designed to operate in fixed cycles with minimal jitter. As a result, FPGAs have been widely explored for accelerating cryptographic functions, packet parsing, and network function virtualization in high-performance networking systems.
The Zynq UltraScale+ platform combines a multi-core ARM Processing System (PS) with tightly coupled Programmable Logic (PL), enabling flexible software–hardware co-design. Running a full-featured operating system such as Ubuntu Linux on the PS allows the use of modern kernel networking frameworks, while the PL can be used to offload compute-intensive tasks. However, integrating Ubuntu-based networking stacks with FPGA acceleration presents practical challenges, including programmable logic configuration from Linux, dynamic hard-ware management, device-tree integration, and efficient PS–PL communication.
This course project explores a complete software–hardware co-design workflow on the Zynq UltraScale+ ZCU102 platform. The project begins with the installation and bring-up of Ubuntu Linux on the quad-core ARM processing system, followed by experimentation with AF XDP–based fast packet processing in user space. The programmable logic is then con-figured dynamically from Ubuntu using bitstream loading and device-tree overlays. A simple programmable logic design is developed to validate AXI interfacing and PS–PL communica-tion. Building on this foundation, a PS–PL co-design framework is implemented to offload cryptographic hash computation to the FPGA fabric. Finally, the project evaluates the performance benefits of hardware acceleration by comparing computation time on the Processing System and Programmable Logic, demonstrating the effectiveness of FPGA-assisted packet processing under Ubuntu Linux.
Figure 1.1 presents the overall project architecture, structured into two complementary ex-perimental phases. The first phase evaluates high-speed packet reception and transmission using the AF XDP framework, enabling zero-copy user-space networking on the Process-ing System (PS). The second phase adopts a hardware–software co-design approach, where SHA-3 hashing is offloaded to a custom accelerator implemented in the Programmable Logic (PL). Control and data exchange between PS and PL are realized through AXI BRAM interfaces, ensuring deterministic operation and low-latency communication. Together, these phases form a unified platform for analyzing software-based packet processing alongside hardware-accelerated cryptographic hashing.
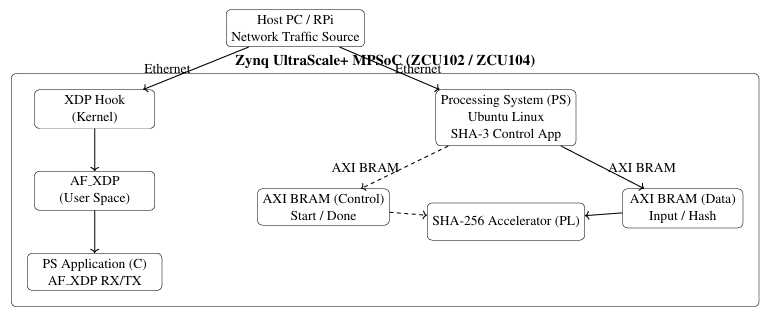
Figure 1.1: Parallel AF XDP packet processing and SHA-3 hardware acceleration experiments on Zynq UltraScale+ MPSoC using AXI BRAM–based PS–PL communication
II.EXPERIMENTAL PLATFROM AND DESIGN RATIONALE
2.1 Target Hardware Platform
The experiments in this course project were carried out on the Xilinx ZCU102 development board, which is based on the Zynq UltraScale+ MPSoC architecture. The platform integrates a quad-core ARM Cortex-A53 Processing System (PS) tightly coupled with a large Programmable Logic (PL) fabric through high-performance AXI interconnects. This heterogeneous architecture enables flexible software execution on the PS while allowing compute-intensive tasks to be offloaded to custom hardware accelerators implemented in the PL.
The ZCU102 platform provides high-speed Ethernet connectivity, sufficient on-chip memory resources, and support for dynamic programmable logic configuration, making it suit-able for investigating software–hardware co-design for network packet processing and cryptographic acceleration.

(a) ZCU102 development board
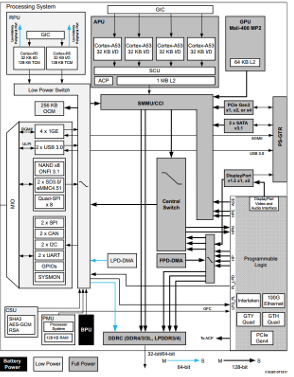
(b) Zynq UltraScale+ MPSoC architecture
Figure 2.1: ZCU102 experimental platform: development board and Zynq UltraScale+ architecture
2.2 Operating System Selection
Ubuntu Linux was selected as the operating system for this project due to its full-featured kernel support and rich development ecosystem. In particular, Ubuntu enables the use of modern kernel networking frameworks such as extended Berkeley Packet Filter (eBPF), Express Data Path (XDP), and AF XDP sockets, which are essential for fast packet processing experiments. Additionally, Ubuntu provides access to standard C/C++ toolchains, kernel debugging utilities, and user-space libraries required for developing and evaluating networking applications.
Unlike bare-metal or minimal Linux environments, Ubuntu allows kernel-level experimentation while preserving user-space flexibility, which is critical for evaluating end-to-end packet processing pipelines involving both software and hardware components.
2.3 Platform Selection: Options Considered
Several alternative platforms and software stacks were evaluated before selecting Ubuntu on Zynq UltraScale+. A bare-metal Ethernet implementation was unsuitable, as it lacks kernel networking support and cannot leverage XDP or AF XDP. PYNQ-based platforms were also considered; however, their Python-centric abstraction hides low-level AXI interfaces and does not provide access to kernel networking internals, making them unsuitable for fast-path packet processing research. Other Zynq-7000–based platforms were limited by kernel driver availability and typically require PetaLinux-based workflows.
Ubuntu on Zynq UltraScale+ was ultimately chosen as it provides a full Linux kernel with support for XDP, AF XDP, and eBPF, along with root access, dynamic device-tree over-lays, and programmable logic memory mapping. Although documentation for Ubuntu on ZCU102/ZCU104 is relatively limited, the platform offers the flexibility required for this project.
2.4 Why FPGA Acceleration is Appropriate
Field Programmable Gate Arrays are well suited for high-performance packet processing and cryptographic workloads. FPGAs provide deterministic execution, massive parallelism, and low jitter, which are critical for networking applications operating at high packet rates. Prior research has demonstrated significant acceleration factors, typically ranging from 5× to 30×, for applications such as deep packet inspection, packet filtering, and cryptographic hashing.
FPGA-based accelerators have been widely explored for SHA-family hashing, match-action pipelines, and SmartNIC-style architectures. These characteristics make FPGAs a strong candidate for per-packet computation and hash-heavy workloads, where predictable latency and sustained throughput are more important than general-purpose programmability.
2.5 Software–Hardware Co-Design Architecture
The overall design philosophy of this project is to combine Linux kernel fast-path packet pro-cessing with FPGA-based computation. The intended architecture follows a staged pipeline in which packets are received by the network interface, processed using XDP or AF XDP mechanisms, delivered to user space, and then forwarded to the Processing System for coordination with programmable logic accelerators. The PL performs compute-intensive operations, after which results are returned to the PS and, if required, transmitted back through the network stack.
This co-design approach reduces CPU load while preserving the flexibility of Linux-based packet processing. It is particularly well suited for embedded network function pipelines that require both programmability and high performance.
2.6 Measured Metrics
To evaluate the effectiveness of the proposed software–hardware co-design, the following met-rics were measured throughout the experiments:
- Cryptographic hashing latency on the Processing System (PS)
- Cryptographic hashing latency on the Programmable Logic (PL)
- End-to-end packet processing delay, including software and hardware components.
These metrics provide quantitative insight into the performance benefits of hardware of floading and form the basis for comparative analysis presented in later chapters.
2.7 Project Objectives and Milestones
The primary objective of this course project is to establish a complete software–hardware co-design pipeline for packet acceleration on the Zynq UltraScale+ platform. Specific goals include enabling XDP and AF XDP–based fast packet ingestion, developing a reliable PS–PL interface using BRAM-based control and data exchange, and offloading compute-intensive hashing to a custom programmable logic accelerator.
The project milestones include successful installation and operation of Ubuntu on the ZCU102 platform, experimentation with AF XDP examples for user-space packet processing, implementation of PS–PL communication mechanisms, exploration of device-tree overlays and AXI address mapping, and integration of a programmable logic pipeline for accelerated SHA computation.
2.8 Challenges Encountered
Ubuntu support for ZCU102 and ZCU104 is relatively recent, resulting in limited documentation and several undocumented configuration steps. Challenges encountered during the project include device-tree integration for programmable logic peripherals, understanding the programmable logic boot sequence, mapping AXI address spaces correctly, and validating AF XDP driver behavior. These challenges required manual experimentation involving kernel configuration, device-tree patching, and iterative testing.
III.UBUNTU INSTALLATION AND BOOT FLOW ON ZCU102
3.1 Ubuntu Installation and Deployment on ZCU102
Ubuntu Desktop 22.04 LTS was used as the operating system for this course project. This re-lease provides long-term support (LTS) until April 2032 and is well suited for extended development and experimentation. Canonical provides a prebuilt Ubuntu image specifically targeted for AMD–Xilinx Zynq UltraScale+ platforms, including the ZCU102, ZCU104, and ZCU106 boards [1].
Ubuntu was deployed on the ZCU102 platform using a unified SD-card image designed for ZCU10x devices. The image includes all essential boot components required for Linux operation and supports a standard partition layout consisting of a FAT partition for boot assets and a root filesystem partition containing the Ubuntu operating system. The image was distributed in compressed .img.xz format and was extracted prior to flashing onto the SD card [2].
After flashing the SD card, the ZCU102 board was configured to boot in SD mode. Upon power-up, Ubuntu booted successfully on the quad-core ARM Cortex-A53 Processing System. The installed operating system provided immediate access to kernel-level networking features, standard development tools, and user-space utilities required for AF XDP-based packet processing and programmable logic integration. Ubuntu was selected primarily due to its compatibility with mainline Linux kernels and its native support for modern networking frameworks such as XDP, AF XDP, and eBPF.
3.2 Certified Ubuntu Installation and Primary System Setup
This section describes the installation and initial configuration of the Certified Ubuntu 22.04 LTS image for Xilinx devices on the ZCU102 platform. The content is based on the official Xilinx and Canonical documentation for certified Ubuntu images [3].
3.2.1 Certified Ubuntu for Xilinx Devices
The Certified Ubuntu 22.04 LTS for Xilinx Devices image is an official Ubuntu distribution released by Canonical with certified hardware support for selected AMD–Xilinx evaluation boards, including the ZCU102, ZCU104, and ZCU106. The image provides a complete desktop Linux environment with validated kernel, device-tree, and boot configurations tailored for Zynq UltraScale+ platforms.
Using a certified image ensures compatibility with the underlying hardware, reduces bring-up complexity, and provides a stable foundation for kernel-level networking experiments and programmable logic integration.
3.2.2 Hardware and Software Requirements
The following hardware and connectivity requirements were used for system installation and initial validation:
- ZCU102 evaluation board (Revision 0 or later)
- SD card with a minimum capacity of 16 GB
- Wired Ethernet connection (100 Mbps or higher) for package installation and updates
- USB peripherals such as keyboard and mouse (optional)
- DisplayPort monitor and cable for graphical desktop access (optional)
- USB UART interface or SSH for headless operation
Although a graphical desktop environment can be used via DisplayPort, all experiments in this project can also be conducted using serial console or SSH-based access.
3.2.3 Installing the Certified Ubuntu Image
The Certified Ubuntu 22.04 LTS image for Xilinx devices was downloaded from the official Canonical distribution site [2]. The image is provided in compressed .img.xz format and was extracted before being written to the SD card.
The extracted image was written to the SD card using a standard disk imaging utility such as Rufus [4]. After flashing, the SD card was inserted into the ZCU102 board, which was then configured to boot in SD mode. The image includes all required boot assets and partitions necessary for successful Ubuntu boot on the platform.
3.2.4 Initial Boot and Login
During the first boot, the system initialization messages can be observed either through the USB UART console or via the connected display. Once the boot process completes, the system presents a login prompt. The default credentials provided with the certified image are:
• Username: ubuntu
• Password: ubuntu
For security reasons, the system enforces a password change upon the first successful login. In cases where the initial login occurs before this enforcement, the password update is required during subsequent logins or when invoking administrative privileges.
3.2.5 Graphical Desktop Environment
When a DisplayPort monitor is connected, the system boots into the Ubuntu 22.04 LTS GNOME 42 graphical desktop environment. The default display resolution is set to 1920×1080. For the ZCU102 platform, this resolution represents the maximum supported configuration due to DisplayPort lane allocation. Higher resolutions are not enabled by default to ensure stability and reliable desktop performance.
3.2.6 Network Configuration and SSH Access
Network connectivity is required for system updates and development workflows. When connected to a network with DHCP support, the system automatically acquires an IP address. Static IP configuration can be performed using standard Linux networking utilities if required. Once network connectivity is established, Secure Shell (SSH) can be used to access the ZCU102 remotely. SSH-based access was primarily used in this project to enable remote development, code deployment, and execution of networking and programmable logic experiments.
3.2.7 Xilinx Development Environment Setup
To support hardware platform management and development workflows, the xlnx-config utility was installed. This utility, provided as a Snap package, enables management of hardware configurations, boot assets, and platform-specific features under Ubuntu [5].
The xlnx-config tool also provides infrastructure for managing custom hardware plat-forms and programmable logic configurations, which is essential for later stages of this project involving dynamic PL programming and device-tree overlays.
3.2.8 System Update and Package Upgrade
Following installation, the system packages were upgraded to the latest available versions to incorporate bug fixes, security patches, and kernel updates. Updating the system ensures stable operation and compatibility with networking tools and FPGA management utilities used in subsequent experiments.
3.3 Booting Certified Ubuntu on ZCU102
This section provides a concise overview of the boot process used by the Certified Ubuntu 22.04 LTS release for the ZCU102 platform. The description is based on the official AMD–Xilinx documentation and is presented to aid understanding of system bring-up, debugging, and programmable logic integration, rather than as a procedural guide [6].
3.3.1 Overview of the Certified Ubuntu Boot Architecture
The Certified Ubuntu for Xilinx Devices release is distributed as a single SD-card image that supports multiple ZCU10x evaluation boards. The image contains a complete Ubuntu operating system along with board-specific boot artifacts and reference programmable logic configura-tions. A unified boot architecture is employed to allow the same SD-card image to be used across supported boards, including the ZCU102.
Figure 3.1 illustrates the high-level boot flow used by the ZCU10x Ubuntu platform.
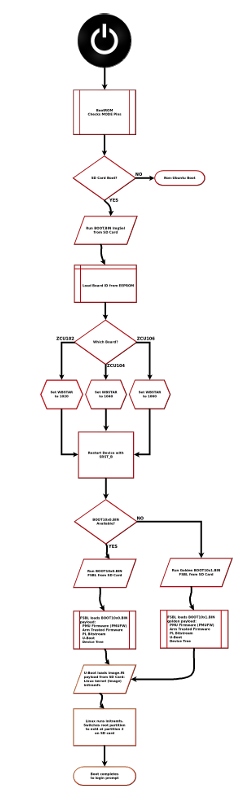
Figure 3.1: Boot process used by the Certified Ubuntu for Xilinx Devices release on ZCU102
3.3.2 Initial Boot Image Selection Using MultiBoot
Upon power-on or a complete system reset, the Zynq UltraScale+ MPSoC BootROM executes and determines the boot mode based on the device configuration pins. When booting from the SD card, the BootROM searches the first FAT/FAT32 partition for a boot image. The Certified Ubuntu image leverages the MultiBoot feature of the Zynq UltraScale+ device to support board-specific boot selection.
For the ZCU102 platform, the initial BOOT.BIN on the SD card contains a minimal Image Selector application rather than a full boot payload. This application identifies the target board using a unique identifier stored in the board EEPROM and programs the MultiBoot register accordingly. The system then performs a soft reset, causing the BootROM to reload and select the appropriate ZCU102-specific boot image.
3.3.3 Active and Golden Boot Images
The Certified Ubuntu release maintains both an Active Image and a Golden Image for each supported board. For the ZCU102, the active configuration file is named boot1020.bin, while the golden fallback image is named boot1021.bin. The golden image represents a known working configuration and provides a recovery mechanism in the event of corruption or mis-configuration of the active image.
Boot configuration and image management are handled by the xlnx-config utility under Ubuntu. When new hardware platforms or demonstrations are installed, this utility generates updated active boot images and updates the MultiBoot configuration to enable seamless reboot into the new setup.
3.3.4 U-Boot and Linux Hand-Off
Following boot image selection, a board-specific First Stage Boot Loader initializes the Pro-cessing System, loads platform firmware, and transfers control to U-Boot. U-Boot is configured to use a Distro Boot mechanism, allowing boot behavior to be modified through scripts without recompiling the bootloader.
U-Boot loads a common Linux kernel image and an initial RAM filesystem from the SD card. The Linux kernel is booted using a device tree corresponding to the selected boot con-figuration. After early system initialization, the root filesystem is switched from the temporary RAM-based filesystem to the persistent ext4 partition on the SD card, enabling state retention across reboots.
3.3.5 Relevance to Programmable Logic Integration
Understanding the Certified Ubuntu boot flow on ZCU102 is essential for safe experimentation with programmable logic configuration. Since the boot image may include a programmable logic bitstream and device tree, incorrect modifications can impact system stability. The presence of a golden image and dynamic boot management through xlnx-config enables controlled experimentation while preserving a reliable recovery path.
IV.AF_XDP-BASED FAST PACKET PROCESSING EXPERIMENTS
4.1 XDP Overview and Fast-Path Design
Express Data Path (XDP) is a high-performance packet processing framework integrated into the Linux kernel networking stack. XDP programs are executed directly in the network driver receive (RX) path, before socket buffer allocation and higher-layer protocol processing. This early execution point enables extremely low-latency packet handling and allows packets to be dropped, redirected, or transmitted without traversing the full kernel networking stack.
Figure 4.1 illustrates the position of XDP within the Linux kernel packet processing pipeline.
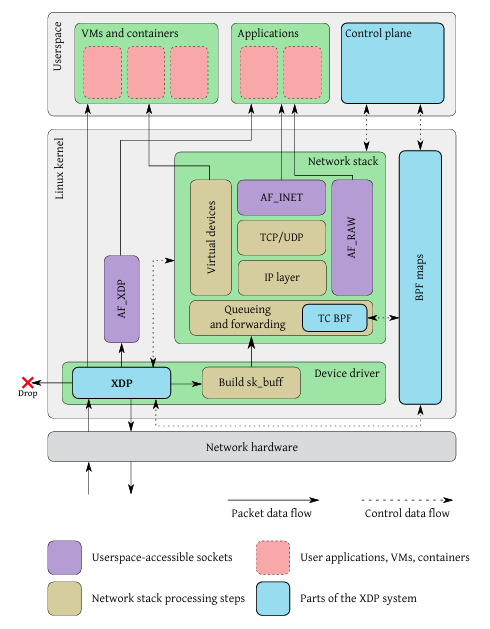
Figure 4.1: XDP fast-path integration within the Linux kernel networking stack
XDP programs are written using the extended Berkeley Packet Filter (eBPF) instruction set. These programs are statically verified for safety and just-in-time (JIT) compiled to native instructions, ensuring both performance and kernel stability. Runtime state and configuration are shared between kernel and user space through BPF maps.
4.2 XDP Execution Model
An XDP program follows a structured execution flow consisting of packet parsing, decision logic, and action selection. Supported actions include forwarding packets to the regular net-working stack (XDPPASS), dropping packets early (XDPDROP), transmitting packets back on the same interface (XDPTX), and redirecting packets to another interface or user-space socket (XDPREDIRECT).
Figure 4.2 shows the logical execution stages of an XDP program.
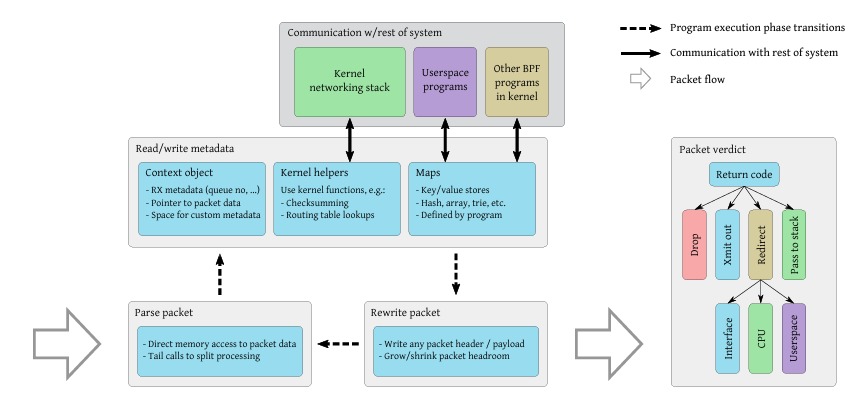
Figure 4.2: XDP program execution flow showing parsing, decision, and action stages
4.3 AF XDP and Zero-Copy Packet Delivery
AF XDP extends the XDP framework by enabling packet delivery directly to user space through a dedicated socket interface. This mechanism allows applications to bypass the traditional Linux networking stack while retaining kernel control over packet reception and dispatch. Early AF XDP implementations relied on copying packet data to user space; however, recent kernel support enables true zero-copy operation through shared user memory (UMEM), subject to network driver support.
Zero-copy AF XDP significantly reduces memory overhead and improves throughput for packet-intensive applications. Experimental results reported in the literature demonstrate packet delivery rates exceeding 20 Mpps on a single CPU core using AF XDP [7]. These characteristics make AF XDP particularly suitable for high-speed networking workloads that require user-space packet processing with minimal latency.
4.4 BPF/XDP and AF_XDP Software Environment Setup
To support XDP and AF XDP experimentation on the ZCU102 platform, a complete BPF/XDP development environment was established under Ubuntu Linux. The setup included compiler toolchains, kernel headers, user-space libraries, and testing utilities required for building, load-ing, and validating eBPF and XDP programs.
Standard development tools, including Clang/LLVM, GCC, and build utilities, were in-stalled along with the running kernel headers to enable compilation of eBPF programs tar-geting the kernel BPF subsystem. Since prebuilt development packages for libbpf were not available for the target ARM-based Ubuntu environment, libbpf was built manually from its official source repository. This ensured availability of the required static library and header files, including bpfhelpers.h, for compiling XDP programs.
The bpftool utility was similarly built from source, as no suitable binary package was available for the platform. The tool was used to inspect loaded BPF programs and maps, as well as to generate the vmlinux.h header from kernel BTF information. This header provides kernel type definitions required for modern CO-RE (Compile Once, Run Everywhere) eBPF development.
During compilation, missing header issues related to kernel and BPF include paths were resolved by installing kernel headers and explicitly including the required system and project header directories. This enabled successful compilation of initial XDP programs using the Clang BPF backend.
For functional testing, a virtual Ethernet (veth) pair was created to form a controlled test environment. IP addressing was configured on the veth interfaces, allowing packet injection and observation without affecting the physical network interface. XDP programs were compiled and attached to the veth interface using the generic XDP attachment mode, and correct program loading was verified through kernel inspection tools. Packet-level validation was performed using ICMP echo traffic to confirm correct XDP execution.
In addition, the xdp-tools package, which provides higher-level utilities for managing XDP programs, was built from source to support advanced experimentation. Together, these components formed a fully functional BPF/XDP development workflow, enabling subsequent AF XDP integration and packet processing experiments on the ZCU102 platform.
4.5 AF XDP User-Space Experiments and Validation
To evaluate AF XDP-based packet redirection and user-space processing, the reference AF XDP user and kernel programs were adapted from the official XDP tutorial repository [8]. The primary focus of the modifications was the user-space application (afxdpuser) and its packet processing routine, where the processpacket() function was extended to explicitly parse and handle both IPv4 and IPv6 ICMP packets redirected from the XDP fast path.
The modified implementation was used to validate correct packet reception, parsing, and response generation in user space while bypassing the conventional Linux socket-based net-working stack. Both the kernel-side XDP program and the user-space AF XDP application were instrumented with counters to observe packet reception, transmission, and redirection behavior during experiments.
4.5.1 Namespace-Based AF XDP Test Environment
AF_XDP experiments were first conducted using Linux network namespaces to enable controlled testing without interfering with the host networking configuration. Two isolated net-work namespaces were connected using a virtual Ethernet (veth) pair, forming a point-to-point topology suitable for deterministic validation of packet flow.
IPv6 addressing was configured on the veth interfaces, and baseline connectivity was verified using ICMPv6 echo requests prior to enabling XDP. Once verified, the AF_XDP user application was launched inside the receiving namespace and bound to the corresponding veth interface. ICMPv6 packets transmitted from the peer namespace were successfully redirected by the XDP program to the AF_XDP socket, resulting in observable packet processing activity in user space.
This namespace-based setup enabled rapid debugging and validation of AF_XDP redirection semantics and confirmed correct interaction between the kernel XDP program and the user-space AF_XDP application.
4.5.2 Deployment on Physical Interface (eth0)
After validating functionality in the namespace-based environment, the modified AF XDP setup was deployed on the physical Ethernet interface (eth0) of the ZCU102 platform. The XDP program was attached directly to the NIC driver RX path, and the AF XDP user application was bound to the same interface.
Both IPv4 and IPv6 ICMP echo packets transmitted from an external host were successfully intercepted at the XDP layer and redirected to user space via the AF XDP socket. This con-firmed that the modified user-space processing logic functioned correctly under real network conditions beyond the virtualized test environment.
4.6 Baseline Network Characterisation
To establish a reference point for subsequent acceleration experiments, baseline network performance was measured using ICMP echo requests between a host PC and the ZCU102 board. A high-rate ICMP flood test was conducted to evaluate link stability and round-trip latency.
Figure 4.3 shows the observed ping statistics during the baseline test.
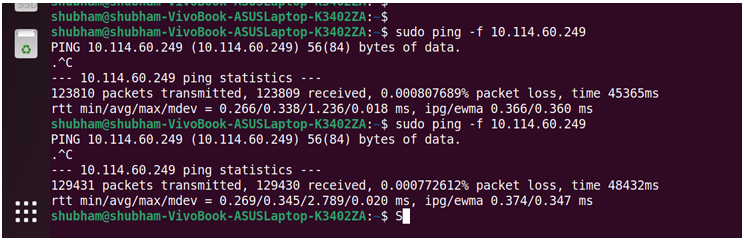
Figure 4.3: ICMP ping measurements between host PC and ZCU102
Two ping experiments were conducted from a host PC to the ZCU102 platform to compare AF XDP-based packet processing with the conventional Linux Ethernet stack. The measured round-trip times exhibited a minimum latency of approximately 0.26 ms and an average latency in the range of 0.33–0.34 ms. The AF XDP-enabled case demonstrates a clear advantage in terms of sustained packet handling capability and reduced packet loss under high-rate traffic. However, the minimum and average round-trip times show no significant improvement, indicating that ICMP latency is largely dominated by network and protocol overheads rather than the receive path alone. These results highlight the potential of AF XDP for high-throughput data-plane acceleration, while also motivating further exploration of FPGA-based offloading to achieve end-to-end latency reduction.
4.6.1 Observations and Limitations
The AF XDP-based processing path demonstrated correct packet interception and redirection for both IPv4 and IPv6 traffic. Namespace-based testing facilitated rapid iteration and debug-ging, while deployment on eth0 validated correctness on real hardware. Although AF XDP significantly reduced kernel networking overhead compared to socket-based processing, the experiments also revealed that overall throughput remained bounded by CPU processing capacity at higher packet rates. These observations motivated the integration of programmable logic accelerators to offload compute-intensive operations in subsequent stages of this project.
4.7 BPF/XDP Installation and AF XDP Test Workflow
This section documents the exact commands and procedures used to install the BPF/XDP toolchain, build required libraries from source, configure a virtual test environment, and vali-date XDP and AF XDP functionality. The commands are included verbatim to ensure reproducibility of the experimental setup on the ZCU102 platform.
4.7.1 BPF/XDP Toolchain Installation
Compiler and Kernel Headers
sudo apt update
sudo apt install clang llvm gcc make git pkg-config libelf-dev libz-dev
sudo apt install linux-headers-$(uname -r)
Building libbpf from Source
Ubuntu ARM/ZynqMP repositories do not provide libbpf-dev. Therefore, libbpf was built manually from the official repository.
git clone https://github.com/libbpf/libbpf.git cd libbpf/src
make
sudo make install
sudo make install_headers
This installs the static library (/usr/lib/libbpf.a) and required headers under /usr/include/bpf/.
Building bpftool and Generating vmlinux.h
git clone https://github.com/libbpf/bpftool.git cd bpftool/src
make
sudo make install
The bpftool binary available via linux-tools was used to inspect loaded programs and generate kernel BTF headers:
sudo find /usr/lib/linux-tools* -name bpftool
sudo /usr/lib/linux-tools/<version>/bpftool prog show sudo /usr/lib/linux-tools/<version>/bpftool btf dump \ file /sys/kernel/btf/vmlinux format c > vmlinux.h
Resolving Missing Header Issues
During initial compilation, missing header errors such as bpf/bpfhelpers.h and asm/types.h were resolved by installing kernel headers, installing libbpf headers, and explicitly specifying include paths during compilation.
clang -O2 -target bpf -I/usr/include -I. \
-c xdp_drop.c -o xdp_drop.o
4.7.2 XDP Test Environment Using Virtual Ethernet
A virtual Ethernet (veth) pair was created to enable controlled XDP testing without affecting the physical network interface.
sudo ip link add veth0 type veth peer name veth1 s
udo ip link set veth0 up
sudo ip link set veth1 up
sudo ip addr add 10.0.0.1/24 dev veth0
sudo ip addr add 10.0.0.2/24 dev veth1
ip addr show veth0
ip addr show veth1
Compiling and Attaching an XDP Program
clang -O2 -target bpf -c xdp_drop.c -o xdp_drop.o
sudo ip link set dev veth1 xdpgeneric obj xdp_drop.o sec xdp_drop
ip link show veth1
XDP behavior was validated using ICMP echo requests.
ping -c 3 10.0.0.1
ping -c 3 10.0.0.2
Handling XDP Loader Conflicts
sudo xdp-loader unload veth1 –all
4.7.3 Installation of xdp-tools
For advanced experimentation, xdp-tools was built from source.
sudo apt install libelf-dev zlib1g-dev libpcap-dev
git clone https://github.com/xdp-project/xdp-tools.git cd xdp-tools
make
sudo make install
4.7.4 Namespace-Based AF XDP Validation
A two-namespace topology was created to validate AF XDP packet redirection using IPv6 traffic.
sudo ip link del vethA 2>/dev/null
sudo ip link del vethB 2>/dev/null
sudo ip netns del nsA 2>/dev/null
sudo ip netns del nsB 2>/dev/null
sudo ip netns add nsA
sudo ip netns add nsB
sudo ip link add vethA type veth peer name vethB
sudo ip link set vethA netns nsA
sudo ip link set vethB netns nsB
sudo ip netns exec nsA ip -6 addr add fc00:1::2/64 dev vethA
sudo ip netns exec nsA ip link set vethA up
sudo ip netns exec nsA ip link set lo up
sudo ip netns exec nsB ip -6 addr add fc00:1::3/64 dev vethB
sudo ip netns exec nsB ip link set vethB up
sudo ip netns exec nsB ip link set lo up
Connectivity was verified prior to enabling XDP:
sudo ip netns exec nsB ping6 fc00:1::2
AF XDP was then attached and validated:
sudo ip netns exec nsA ./af_xdp_user -d vethA –filename af_xdp_kern.o
sudo ip netns exec nsB ping6 fc00:1::2
Finally, the setup was deployed on the physical Ethernet interface:
sudo ./af_xdp_user -d eth0 –filename af_xdp_kern.o
V.CONFIGURING THE PROGRAMMABLE LOGIC ON ZCU102
This chapter describes the complete workflow for programming the Programmable Logic (PL) of the Zynq UltraScale+ MPSoC (ZCU102) under Ubuntu Linux. The approach relies on Linux device tree overlays to dynamically integrate custom PL hardware designs after system boot. This enables runtime hardware reconfiguration without modifying the base boot image or re-booting the system, which is essential for rapid hardware–software co-design experiments.
5.1 Device Tree Overlay Generation and Runtime PL Programming on ZCU102
In this step, the AMD hardware description captured in the custom Programmable Logic (PL) design for the Zynq UltraScale+ MPSoC (ZCU102) must be translated into a format that is un-derstandable by the Linux operating system. Linux represents hardware using a data structure known as the Device Tree (DT). The human-readable representations of device trees are stored in .dts and .dtsi files, while the compiled binary representations are .dtb or .dtbo files.
Since the PL design on ZCU102 is programmed after Linux has already booted, a Device Tree Overlay (DTBO) is generated instead of a static boot-time device tree. Unlike the base Linux device tree, a DT overlay defines fragments that are dynamically applied by the Linux kernel at runtime. These fragments describe PL components such as AXI interconnects, BRAM controllers, clocks, GPIOs, and custom accelerators, allowing the kernel to discover newly instantiated hardware without rebooting the system [9].
The .dts/.dtsi files can be generated in multiple ways, all of which require the hard-ware description captured in the XSA or bitstream file. After the .dtsi file is generated, it is compiled into a binary .dtbo file. The resulting .dtbo file is expected to reside in the Linux firmware directory and is applied dynamically at runtime.
5.1.1 Tools and Inputs Required
The following tools and design artifacts are required for generating and deploying a PL device tree overlay on ZCU102:
• XSCT (Xilinx Software Command-Line Tool), provided with Vivado or Vitis
• Device Tree Generator (DTG), aligned with the Vivado/Vitis version
• Device Tree Compiler (DTC)
• Hardware design handoff file (.xsa)
• PL bitstream file (.bit)
The DTG repository is obtained and checked out as follows:
git clone https://github.com/Xilinx/device-tree-xlnx cd device-tree-xlnx
git checkout xlnx_rel_v<version>
The Device Tree Compiler can be built from source if not already available:
git clone https://git.kernel.org/pub/scm/utils/dtc/dtc.git cd dtc
make
export PATH=$PATH:/<path-to-dtc>/dtc
5.1.2 Generating the Overlay .dtsi from the XSA
The PL hardware description is exported from Vivado as an .xsa file. Using XSCT, the Hard-ware Software Interface (HSI) invokes the Device Tree Generator to produce an overlay .dtsi file.
The following commands are executed:
hsi open_hw_design PL_SHA_2.xsa hsi set_repo_path ../../dtg
hsi create_sw_design device-tree -os device_tree -proc psu_cortexa53_0 hsi set_property CONFIG.dt_overlay true [hsi::get_os]
hsi generate_target -dir ./dt_output
hsi close_hw_design [hsi current_hw_design] exit
The [currenthwdesign] identifier is reported in the output of the hsi openhwdesign command. Upon completion, a directory is created containing pl.dtsi, which describes the PL IP blocks, AXI address regions, clocks, GPIOs, and BRAMs using overlay fragments. Minor manual edits may be required before compilation.
5.1.3 Compiling the Overlay Using DTC
The human-readable pl.dtsi file is compiled into a binary overlay using the Linux Device Tree Compiler. This step converts the textual hardware description into a format that can be consumed directly by the Linux kernel.
The compilation command is:
dtc -O dtb -o pl.dtbo -b 0 -@ pl.dtsi
Here, -O dtb specifies the output format, -o defines the output file name, and the -@ op-tion enables symbol generation, which is mandatory for device tree overlays. The generated pl.dtbo file represents the runtime-loadable PL hardware description for ZCU102.
5.1.4 Bitstream Packaging for Linux FPGA Manager
To program the PL at runtime, the FPGA bitstream must be converted into a Linux-compatible binary format. A minimal Boot Image Format (BIF) file is created as follows:
all:
{
[destination_device = pl] pl.bit
}
The bitstream binary is generated using bootgen:
bootgen -image bin_file.bif -arch zynqmp -process_bitstream bin -w -o pl.bin
This produces pl.bin, which can be loaded by the Linux FPGA Manager on ZCU102.
5.1.5 Runtime Programming of the PL
At runtime, the existing PL configuration is cleared using:
sudo fpgautil -R
The new PL bitstream and corresponding device tree overlay are then applied:
sudo fpgautil -o pl.dtbo -b PL_SHA.bin
This command programs the PL fabric and dynamically applies the device tree overlay. Linux configures the AXI regions, enables clocks, and maps PL peripherals, making them immediately accessible to kernel drivers and user-space applications without requiring a system reboot.
5.2 Summary
This chapter presented a complete and reproducible workflow for programming the Programmable Logic on ZCU102 under Ubuntu Linux. By combining device tree overlays with runtime bit-stream loading, the platform enables flexible and efficient hardware–software co-design, forming the foundation for integrating FPGA accelerators into Linux-based packet processing and cryptographic applications.
5.3 Boot-Time PL Configuration Using Xilinx Package Manager (PAC)
In the current implementation, the Programmable Logic (PL) on the Zynq UltraScale+ ZCU102 platform is configured dynamically at runtime using fpgautil in conjunction with device-tree overlays. This approach provides flexibility during experimentation and rapid iteration under Ubuntu Linux. In addition to runtime configuration, AMD/Xilinx also supports a boot-time platform management mechanism based on the xlnx-config utility and the concept of a Platform Assets Container (PAC) [10]. This mechanism is briefly described here and identified as a direction for further exploration.
5.3.1 Overview of PAC and xlnx-config on ZCU102
From a ZCU102 perspective, PAC-based management enables bundling of boot assets—including the PL bitstream, device tree (system.dtb), firmware components, and optional accelerator bi-naries (e.g., xclbin)—into a structured container. These assets are applied at boot time while preserving the vendor-provided golden boot configuration delivered with Certified Ubuntu for Xilinx Devices. This enables safe rollback and controlled activation of custom hardware plat-forms.
The xlnx-config snap is a command-line tool provided by AMD/Xilinx for managing and manipulating hardware platforms on ZCU102/4/6 and KV260 boards running Certified Ubuntu. It supports platform management, Xilinx-specific system initialization, and controlled access to accelerator binaries for confined application snaps. For ZCU10x devices, xlnx-config man-ages the installation and activation of custom boot assets using a bootgen.bif file, generating a new boot image that takes precedence over the default boot assets after a system reboot. Only board-specific assets corresponding to the detected platform (e.g., ZCU102) are exposed and activated.
5.3.2 Device Tree Compilation for Boot-Time Integration
For boot-time PL integration, device trees are typically compiled into a monolithic system.dtb that matches the contents of the PL bitstream. The following commands illustrate preprocessing and compilation of the device tree source:
gcc -I my_dts -E -nostdinc -I include -undef -D DTS \
-x assembler-with-cpp -o system.dts system-top.dts
dtc -I dts -O dtb -o system.dtb system.dts
The generated system.dtb is included as part of the PAC boot assets and is intended to be loaded together with the corresponding PL bitstream during system boot.
5.3.3 Platform Assets Container Structure and Activation
A Platform Assets Container contains board-specific boot assets organized under a structured directory hierarchy. For ZCU102, these assets typically include the PL bitstream, device tree, firmware components, and a bootgen.bif file used to generate the boot image. Once prepared, the PAC can be manually installed by copying it into the firmware partition:
sudo cp -r ~/test_pac_2 /boot/firmware/xlnx-config/
The desired platform configuration is then activated using the xlnx-config utility:
sudo xlnx-config -a test_platform-fooV2
Upon activation, xlnx-config generates a new boot image using the provided bootgen.bif, updates the boot assets under /boot/firmware, records the active configuration, and updates the multiboot register. A system reboot is required for the new PL configuration to take effect.
5.3.4 Discussion and Scope
In this project, PAC-based boot-time PL configuration was not extensively implemented. In-stead, runtime PL loading using fpgautil and device-tree overlays was preferred to support rapid experimentation, debugging, and iterative development under Ubuntu Linux. Embedding the PL bitstream and device tree directly into the boot image via a bootgen.bif can reduce configuration latency but introduces additional complexity and a higher risk of boot failure if misconfigured. Therefore, boot-time PL integration using PACs was intentionally deferred and must be approached with caution on ZCU102 systems to avoid disrupting the golden boot assets.
Nevertheless, the PAC and xlnx-config framework represents a robust and scalable approach for production-oriented ZCU102 deployments, where controlled boot-time activation of PL designs, firmware, and device trees is desirable. Future work can investigate PAC-based deployment for stable end-to-end pipelines in which the hardware configuration is fixed and benefits from early boot-time activation.
VI.PS-PL INTERFACE AND MEMORY VALIDATION
This chapter presents the design and validation of a BRAM-based communication interface between the Processing System (PS) and Programmable Logic (PL) on the Zynq UltraScale+ MPSoC (ZCU102). The objective of this phase is to establish a reliable, memory-mapped PS–PL interface under Ubuntu Linux, serving as a foundation for subsequent hardware accelerators. Two AXI BRAM controllers are employed to clearly separate control signaling from bulk data transfer, enabling deterministic access and simplified software interaction.
6.1 Overview of BRAM-Based PS–PL Interface
The PS–PL interface is implemented using two independent Block RAM (BRAM) instances instantiated in the PL and exposed to the PS through AXI BRAM Controllers. Both BRAMs are mapped into the PS physical address space via the AXI interconnect and described using a runtime device tree overlay.
- Control BRAM: Used for low-bandwidth control and status exchange. Typical fields include start flags, done flags, mode selection, and status indicators. The PS performs write operations to initiate hardware actions, while the PL updates status fields that are polled by software.
- Data BRAM: Used for high-bandwidth data transfer between PS and This memory region carries input data written by the PS and output data produced by the PL, such as hash values or intermediate results.
Separating control and data paths simplifies software design, avoids contention, and closely mirrors the architecture used in later accelerator modules.
6.2 PL Build Flow and Runtime Deployment
The PL design containing the two BRAMs and AXI infrastructure is first synthesized and implemented in Vivado. From this design, two artifacts are generated:
• FPGA bitstream (.bit) for programming the PL fabric
• Hardware handoff file (.xsa) capturing the complete hardware description
The .xsa file is used to generate the device tree overlay source (pl.dtsi) using XSCT and the Device Tree Generator, as described in the previous chapter. The pl.dtsi file is compiled into a binary overlay (pl.dtbo) using the Device Tree Compiler. In parallel, the PL bitstream is packaged into a Linux-compatible binary (pl.bin) using bootgen.
At runtime on ZCU102 running Ubuntu Linux, the existing PL configuration is cleared and the new design is applied dynamically using fpgautil, loading both pl.bin and pl.dtbo. This enables Linux to configure AXI address regions and expose the BRAMs to user-space applications without rebooting the system.
6.3 BRAM Address Mapping and Access Model
Once the device tree overlay is applied, both BRAMs appear as memory-mapped regions in the PS physical address space. Each BRAM is accessed as a contiguous array of 32-bit words. The address mapping is fixed at design time in Vivado and reflected in the device tree overlay.
In the validation setup, the Data BRAM is mapped starting at a known AXI base physical address. The PS accesses this region directly using memory-mapped I/O, allowing software to write test patterns and read back results produced by the PL.
6.4 User-Space BRAM Validation Using /dev/mem
To validate correct PS–PL memory interaction, a user-space C program is developed that directly maps the BRAM physical address into the process virtual address space using /dev/mem. This approach avoids kernel driver complexity and provides a transparent mechanism to verify address mapping, data integrity, and read/write correctness.
The program begins by querying the system page size and aligning the BRAM base physical address to the nearest page boundary. This alignment is required because mmap() operates at page granularity. The BRAM region is then mapped with read and write permissions.
A pointer is constructed to access the first 32-bit word at the BRAM base address. Using this pointer, the software writes a deterministic test pattern across the entire BRAM region. The chosen pattern combines a fixed constant with the word index, ensuring that each memory location contains a unique value.
After the write phase, the program reads back every location and compares the observed value against the expected pattern. Any mismatch is reported along with the corresponding address and index. A summary is printed indicating the total number of locations tested and whether the validation passed or failed.
Successful completion of this test confirms:
• Correct AXI address mapping from PS to PL
• Reliable write and read access to BRAM under Ubuntu
• Absence of data corruption or alignment errors
This validation step establishes confidence in the PS–PL communication infrastructure and serves as a prerequisite for integrating more complex PL accelerators.
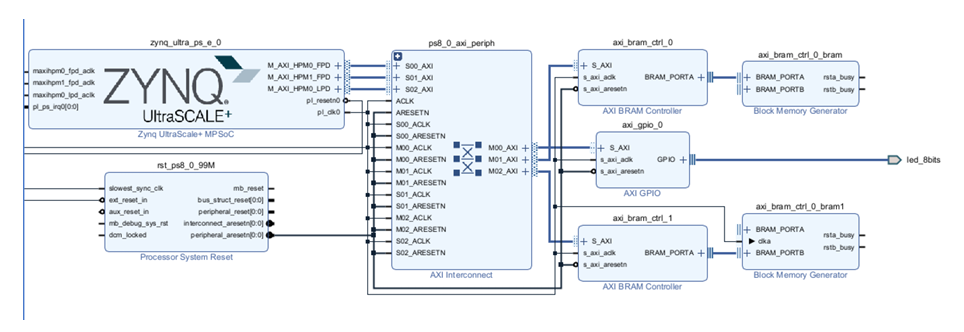
Figure 6.1: Vivado block design of the PS–PL BRAM test setup on ZCU102. The Processing System interfaces with two AXI BRAM controllers in the Programmable Logic, enabling memory-mapped control and data exchange for PS–PL validation under Ubuntu Linux
6.5 Summary
This chapter demonstrated a complete PS–PL memory validation workflow on ZCU102 using dual BRAMs and runtime device tree overlays. By combining a clean separation of control and data memories with direct user-space validation, the design confirms reliable AXI-based com-munication under Linux. The verified BRAM interface forms the foundation for subsequent chapters that introduce FPGA-based computation and hardware acceleration.
VII.SHA-3 HARDWARE ACCELERATION AND PS-PL BRAM-BASED COMMUNICATION ON ZCU102
7.1 Chapter Overview
This chapter presents the design and validation of a SHA-3 hardware accelerator implemented in the Programmable Logic (PL) of the Zynq UltraScale+ MPSoC (ZCU102) and its interac-tion with the Processing System (PS) under Ubuntu Linux. A BRAM-based communication architecture is employed to enable deterministic, memory-mapped data exchange between PS and PL. The chapter details the interface architecture, handshake protocol, address mapping, hardware structure, and validation methodology used to ensure reliable operation.
7.2 PS–PL Communication Architecture
The PS–PL interface is implemented using two AXI BRAM controllers and a dedicated GPIO reset line. This architecture cleanly separates control signaling from data movement and en-ables predictable, low-latency interaction between software and hardware components.
7.2.1 BRAM Roles and Address Usage
Two independent BRAM instances are instantiated in the PL and mapped into the PS physical address space.
• Data BRAM
- Address locations 1–16 store the input packet written by the
- Address locations 32–39 store the SHA-3 hash output written by the
- Accessed as 32-bit memory-mapped words by both PS and
• Control BRAM
- Lower 16 bits written by the PS indicate that the input packet has been
- Upper 16 bits written by the PL indicate completion of hash
- Used as a lightweight handshake and status
7.2.2 GPIO Reset Mechanism
A single-byte GPIO line from the PS is used to reset the PL finite state machine (FSM) and SHA-3 pipeline. This ensures deterministic initialization of the hardware accelerator before each experiment and avoids residual state across packet processing cycles.
7.3 PS–PL Handshake Protocol
The PS and PL interact through a simple polling-based handshake mechanism implemented using the Control BRAM. The protocol proceeds as follows:
- The PS writes the input packet into the Data
- The PS sets the LSB flag in the Control
- The PL detects the flag and begins SHA-3
- The PL writes the hash output into the Data
- The PL sets the MSB flag in the Control
- The PS reads the hash output and clears the control
This approach avoids interrupts and ensures deterministic execution timing.
7.4 SHA-256 Hardware Accelerator Architecture
The SHA-256 accelerator implemented in the PL is based on the Keccak permutation and follows a deterministic FSM-driven architecture.
- Round core derived from open-source reference
- FSM controlling absorb, permutation, and squeeze
- GPIO-based reset for deterministic
7.5 AXI Address Mapping
The AXI address mapping between PS and PL is fixed during Vivado design and reflected in the device tree overlay applied at runtime.
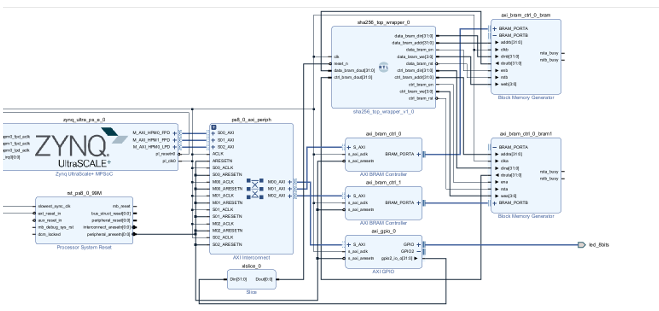
Figure 7.1: Block-level architecture of the SHA-3 hardware accelerator implemented in the PL
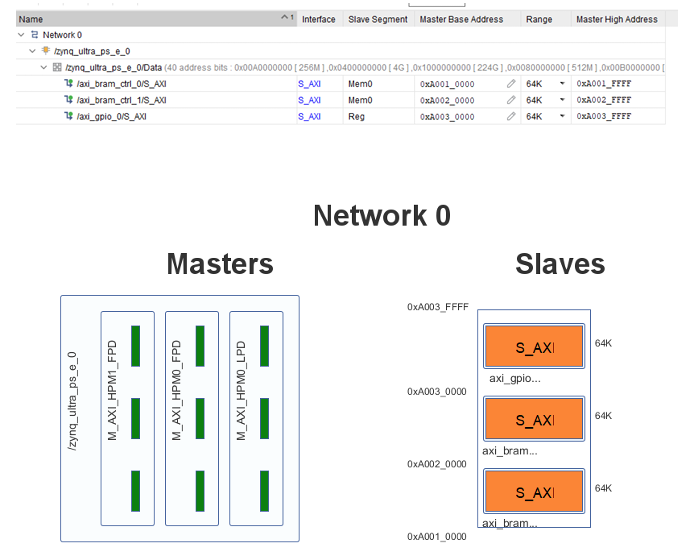
Figure 7.2: AXI address mapping between PS and PL showing control and data BRAM regions on ZCU102
7.6 Summary
This chapter presented the design and validation of a BRAM-based PS–PL communication framework for a SHA-3 hardware accelerator on ZCU102. The use of dual BRAMs, GPIO-based reset, and a flag-driven handshake protocol enables deterministic and reliable interaction under Ubuntu Linux. This validated infrastructure forms the foundation for performance eval-uation and hardware acceleration experiments presented in subsequent chapters.
VIII.FPGA IMPLEMENTATION AND SHA COMPUTATION RESULTS
8.1 Chapter Overview
This chapter presents the experimental evaluation of the proposed packet processing and SHA-3 hardware acceleration framework implemented on the Zynq UltraScale+ MPSoC (ZCU102). The experiments focus on validating functional correctness, measuring computation latency, and comparing FPGA-based hashing against software execution under Ubuntu Linux. Results are presented using implementation snapshots, comparative plots, and measured timing statistics.
8.2 FPGA Implementation Results
Figure 8.1 shows the FPGA implementation results obtained after synthesis and implementa-tion of the SHA-3 accelerator in the Programmable Logic. The design meets timing constraints and demonstrates successful integration of the Keccak core, control FSM, AXI BRAM inter-faces, and PS–PL interconnect.
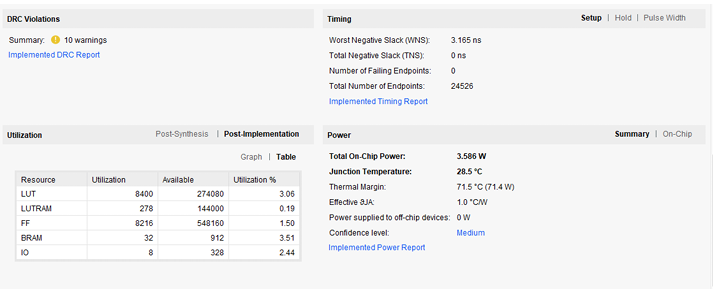
Figure 8.1: FPGA implementation results of the SHA-3 hardware accelerator on ZCU102
The implementation confirms that the accelerator can be reliably deployed in the PL while maintaining compatibility with the PS interface and runtime device tree overlay mechanism.
8.3 Hash Computation Comparison Results
To validate correctness and consistency, hash outputs produced by the FPGA accelerator were compared against software-generated SHA-3 hashes. Figure 8.2 illustrates the matching be-havior between hardware and software outputs for identical input data.
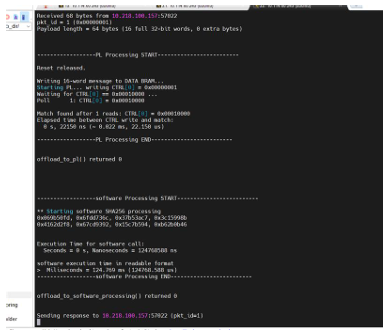
Figure 8.2: Comparison of SHA-3 hash computation results between FPGA (PL) and software (PS)
The observed agreement across all tested inputs confirms the functional correctness of the hardware implementation.
8.4 SHA-3 Performance Evaluation
8.4.1 Measured Latency
The latency of SHA-3 computation was measured for both FPGA-based and software-based implementations. The results are summarized below:
- FPGA (PL) SHA-3: 15 µs
- Software (PS, Ubuntu): 124.768 ms
These measurements clearly demonstrate the computational advantage of hardware acceleration.
8.4.2 Hardware Acceleration Characteristics
The FPGA implementation achieves low and deterministic latency due to the following factors:
• Fully pipelined, fixed-cycle Keccak-f[1600] core
• Absence of operating system scheduling, context switching, and cache effects.
• Direct BRAM-based data access with minimal control overhead.
As a result, the accelerator exhibits predictable timing behavior with negligible jitter.
8.4.3 Software Execution Characteristics
In contrast, the software implementation executed on the Processing System under Ubuntu Linux exhibits significantly higher latency due to:
- CPU scheduling delays and context
- Memory copy overheads between user space and kernel
- Function-call and library execution
Additionally, execution time varies under system load, making software hashing unsuitable for latency-critical workloads.
8.5 Overall Performance Comparison
The FPGA-based SHA-3 accelerator achieves an improvement of approximately 5632× over the software implementation. This result highlights the effectiveness of offloading crypto-graphic hashing to dedicated hardware, particularly in high-throughput or real-time packet processing applications.
8.6 Summary
This chapter presented a comprehensive experimental evaluation of the proposed SHA-3 hard-ware acceleration framework. Implementation results confirmed successful deployment on ZCU102, functional validation demonstrated correctness, and performance measurements showed orders-of-magnitude latency improvement over software execution. These results motivate the use of FPGA-based cryptographic acceleration for secure and high-performance network packet processing.
IX.END TO END ACCELERATION PIPELINE: EXPERIMENTS AND RESULTS
9.1 Chapter Overview
This chapter presents an end-to-end experimental evaluation of the proposed UDP packet processing and SHA-3 acceleration pipeline implemented on the Zynq UltraScale+ MPSoC (ZCU102). The pipeline integrates packet reception, cryptographic hashing, and packet trans-mission, supporting both software-based and hardware-accelerated execution paths. Experimental results are reported for Processing System (PS), Programmable Logic (PL), and combined PS–PL configurations, with a focus on computation latency and end-to-end delay.
9.2 Experimental Setup
9.2.1 ZCU102 Hardware Setup
The experimental setup used for end-to-end evaluation is shown in Figure 9.1. The ZCU102 board is connected to a host system via Ethernet for UDP packet injection and response mea-surement. A USB-UART connection provides console access for debugging and logging. Suc-cessful loading of the PL bitstream is confirmed through the green DONE LED on the board, ensuring that the hardware accelerator is active before experiments commence.
This setup enables controlled packet-level experiments while allowing precise timing measurements on both PS and PL execution paths.
9.3 End-to-End Characterisation Pipeline
The characterisation pipeline used for the experiments is structured as follows.
- A UDP packet generator implemented in Python transmits packets containing a 4-byte packet identifier followed by a 512-bit payload.
- A UDP socket receiver implemented in C executes on the PS under Ubuntu
- Received packets are forwarded to either:

Figure 9.1: Experimental setup showing the ZCU102 board connected to a host PC via Ethernet and USB-UART
- Case 1: SHA-3 hashing offloaded to the PL accelerator, or
- Case 2: SHA-3 hashing executed entirely in software on the
- The computed hash is transmitted back to the packet source for verification.
The following metrics are measured:
- Software hashing latency,
- Hardware hashing latency,
- End-to-end packet processing
This pipeline enables a direct and fair comparison between PS and PL execution paths.
9.4 PL Hashing Timing Results
Figure 9.2 presents the transmit (TX) and receive (RX) timing measurements when SHA-3 hashing is offloaded entirely to the PL. The plots capture the timing distribution for hashing operations within the programmable logic.
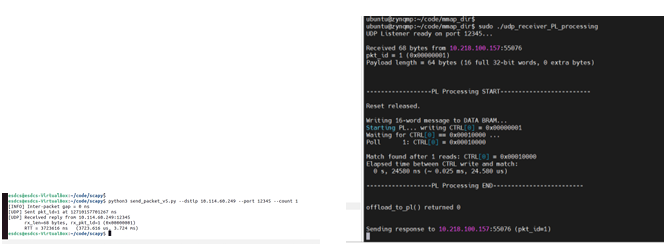
Figure 9.2: PL hashing timing results: transmit (TX) and receive (RX) paths
The results show tightly clustered timing values for both transmit and receive paths, reflecting the fixed-cycle execution behavior of the SHA-3 accelerator in the Programmable Logic. The observed consistency confirms that the PL execution path operates deterministically and is independent of operating system scheduling effects or software-induced overheads.
9.5 PS Hashing Timing Results
Figure 9.3 shows the corresponding transmit and receive timing measurements when SHA-3 hashing is executed entirely in software on the PS under Ubuntu Linux.
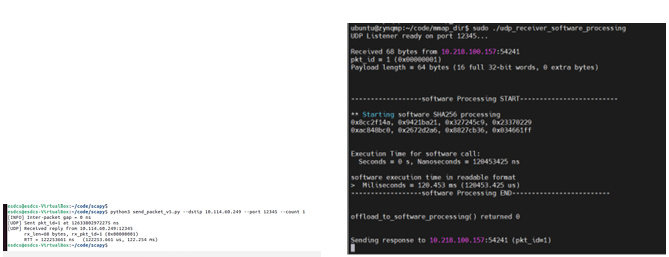
Figure 9.3: PS hashing timing results: transmit (TX) and receive (RX) paths
Compared to the PL-based implementation, the PS hashing results exhibit significantly higher latency and increased variability across measurements. This behavior is attributed to CPU scheduling effects, memory copy overheads, and software execution variability inherent to a general-purpose operating system such as Ubuntu Linux.
9.6 Combined PS–PL Hashing Path
Figure 9.4 illustrates the combined PS–PL hashing path, where packets traverse both software and hardware components before transmission.
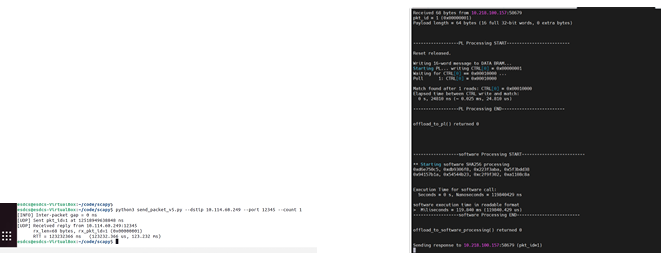
Figure 9.4: Combined PS–PL hashing path showing transmit (PS → PL) and receive (PL →PS) timing
While the PL accelerator provides fast hash computation, the overall latency in the combined PS–PL configuration is dominated by the software processing stages. This observation highlights the importance of minimizing PS involvement in the critical path to fully realize the performance benefits of hardware acceleration.
9.7 Latency and End-to-End Delay Comparison
A quantitative comparison of computation latency and end-to-end delay is summarized in Table 9.1. The measurements correspond to a bidirectional UDP test setup between a Raspberry Pi and the ZCU102 platform.
Table 9.1: Latency and end-to-end delay comparison for PS and PL hashing paths

The bidirectional test setup operates as follows: the Raspberry Pi sends UDP packets con-taining an identifier and payload to the ZCU102. The ZCU102 hashes the payload using either PS or PL execution paths and returns the hash along with timing information to the source. The results indicate that PL-based SHA-3 offloading achieves significantly lower computation latency and end-to-end delay compared to software hashing on the PS. In contrast, configurations involving PS computation exhibit higher latency due to operating system and software overheads, confirming that the PL execution path provides the most efficient and deterministic performance.
9.8 End-to-End Delay Across Multiple Packets
To study consistency across multiple packets, end-to-end delay was measured for 10 packets transmitted at a rate of 2 packets per second. Figure 9.5 compares the PL and PS execution paths.
The PL-based pipeline exhibits consistent and stable end-to-end delay across all packets, demonstrating deterministic behavior under repeated transmissions. In contrast, the PS-based pipeline shows higher latency and greater variability, further reinforcing the advantages of hardware-accelerated hashing for latency-sensitive packet processing.
9.9 Summary
This chapter presented a comprehensive end-to-end experimental evaluation of the proposed packet processing and SHA-3 acceleration pipeline on ZCU102. Hardware offloading to the PL achieves deterministic computation latency and significantly reduces CPU involvement. End-to-end measurements demonstrate that the PL-based path consistently outperforms software execution, particularly in latency-critical packet processing scenarios.
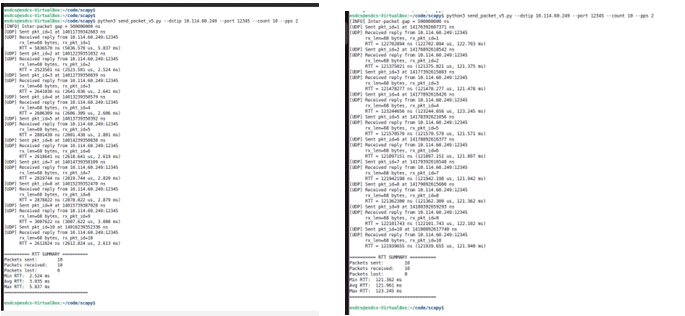
Figure 9.5: End-to-end delay comparison for 10 packets at 2 pps under PL and PS execution paths
X.CONCLUSION AND FUTURE SCOPE
10.1 Conclusion
This course project presented a complete software–hardware co-design workflow for accelerated packet processing on the Zynq UltraScale+ MPSoC (ZCU102) platform. The work began with the installation and bring-up of Ubuntu Linux on the quad-core ARM Processing System, followed by experimentation with XDP and AF XDP–based fast packet processing in user space. These experiments established a high-performance software data path capable of zero-copy packet reception and transmission.
Building on the software foundation, the project explored dynamic configuration of the Programmable Logic from Ubuntu using runtime bitstream loading and device tree overlays. A simple PL-based design was first developed to validate AXI interfacing and PS–PL communication, ensuring correct address mapping, memory access, and handshake behavior. This step provided a reliable baseline for more advanced hardware integration.
Subsequently, a PS–PL co-design framework was implemented to offload SHA-3 crypto-graphic hash computation to the FPGA fabric. The accelerator was integrated using BRAM-based control and data interfaces, GPIO-based reset, and a deterministic handshake proto-col. Experimental results demonstrated that the FPGA-based SHA-3 implementation achieves orders-of-magnitude improvement in computation latency compared to software execution on the Processing System, while also providing predictable and stable timing characteristics.
Overall, the project successfully demonstrated an end-to-end accelerated packet processing pipeline under Ubuntu Linux, combining AF XDP–based networking with FPGA-based cryp-tographic acceleration. The results highlight the effectiveness of FPGA-assisted computation in reducing CPU involvement and achieving deterministic performance, establishing a scalable and flexible framework for Ubuntu-based, FPGA-enabled networking applications.
10.2 Future Scope
While the current implementation validates the feasibility and benefits of software–hardware co-design on ZCU102, several extensions can be explored to further enhance the system:
• Extend the pipeline to a fully integrated AF XDP ‘ FPGA ‘ AF XDP data path using DMA-based transfers, eliminating intermediate software copies.
• Investigate NF chaining and FLASH-style multi-stage packet processing pipelines to support complex networking workloads on embedded SoCs.
• Integrate additional Programmable Logic accelerators, such as packet parsing engines, encryption/decryption blocks, and lightweight machine learning inference modules.
• Revisit automated design flows using MATLAB SoC, HDL, and GPU Coder to evaluate productivity and performance trade-offs once toolchain dependencies are resolved.
These directions provide a clear roadmap for extending the current framework toward more advanced, high-throughput, and intelligent network processing systems leveraging FPGA acceleration under Linux.
BIBLIOGRAPHY
[1] Canonical Ltd., “Ubuntu desktop for amd–xilinx zynq ultrascale+ platforms.” https://ubuntu.com/download/amd#zynq-ultrascale, 2022. Accessed: December 2025.
[2] Canonical Ltd., “Ubuntu desktop 22.04 lts image for zcu10x platforms.” https://people.canonical.com/~platform/images/xilinx/zcu-ubuntu-22. 04/iot-limerick-zcu-classic-desktop-2204-x05-2-20221123-58.img.xz, 2022. Direct SD-card image download, accessed December 2025.
[3] AMD–Xilinx, “Getting started with certified ubuntu 22.04 lts for xilinx devices.” https://xilinx-wiki.atlassian.net/wiki/spaces/A/pages/2363129857/ Getting+Started+with+Certified+Ubuntu+22.04+LTS+for+Xilinx+Devices, 2023. Accessed: December 2025.
[4] Rufus Project, “Rufus: Create bootable usb drives.” https://rufus.ie/en/. Accessed: December 2025.
[5] Canonical Ltd., “xlnx-config utility for ubuntu on xilinx devices.” https://snapcraft. io/xlnx-config. Accessed: December 2025.
[6] AMD–Xilinx, “Booting certified ubuntu for xilinx devices.” https://xilinx-wiki. atlassian.net/wiki/spaces/A/pages/2036826124/Booting+Certified+ Ubuntu+for+Xilinx+Devices, 2023. Accessed: December 2025.
[7] T. Høiland-Jørgensen, J. D. Brouer, D. Borkmann, J. Fastabend, T. Herbert, D. Ahern, and D. Miller, “The express data path: Fast programmable packet processing in the oper-ating system kernel,” in Proceedings of the 2018 Conference of the ACM Special Interest Group on Data Communication (SIGCOMM), (New York, NY, USA), Association for Computing Machinery, 2018.
[8] xdp-project, “Xdp tutorial: Advanced af xdp examples.” https://github.com/ xdp-project/xdp-tutorial/tree/main/advanced03-AF_XDP. Accessed: Decem-ber 2025.
[9] AMD Xilinx, “Device tree overlay generation.” https://xilinx.github.io/ kria-apps-docs/creating_applications/2022.1/build/html/docs/dtsi_dtbo_generation.html, 2022. Accessed for Zynq UltraScale+ device tree overlay workflow.
[10] AMD Xilinx, “Snaps – xlnx-config snap for certified ubuntu on xilinx devices.” https://xilinx-wiki.atlassian.net/wiki/spaces/A/pages/2057043969/ Snaps+-+xlnx-config+Snap+for+Certified+Ubuntu+on+Xilinx+Devices, 2023. Platform Assets Container (PAC) and boot-time hardware management for ZCU10x platforms.
Recent Comments