Design Requirement
- To implement a Neural Network to recognize hand-written digits on TM4C123GH6PM board
- Source Code: git-hub repository

TIVA board with TM4C123GH6PM micro-controller Source: https://in.element14.com/texas-instruments/ek-tm4c123gxl/launchpad-tiva-c-evaluation-kit/dp/2314937
Resources Required
# Tivaware Libraries : Available on http://software-dl.ti.com/tiva-c/SW-TM4C/latest/index_FDS.html # Dev environment with ARM Compiler such as Keil u vision. Code Composer Studio(CCS). (This code was developed on Code Composer Studio) https://software-dl.ti.com/ccs/esd/documents/ccs_downloads.html # PC with Linux OS # USB to Micro USB cable
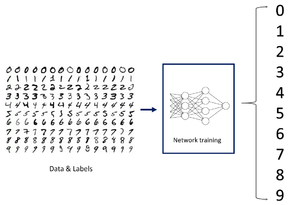
Handwritten Digits Recognition using Neural Networks Flow Diagram
Project Description
- Implements a fast Neural Network to identify handwritten digits on Tiva board.
- A 4-layer Perceptron is trained on MNIST dataset.
- Training is performed on TensorFlow.
- The Trained Model obtained using “TensorFlow” contains a total of 784 input features with ~21000 model parameters which is too large to fit into Tiva board which has an onboard SRAM capacity of only 8 kB.
- Also, the model parameters are single-point float numbers(32 bit). Floating point multiplications are expensive in terms of time and micro-controller resources and Neural networks vastly consist of Multiply-and-accumulate operations. Thus, for efficient neural network inference, several neural network compression techniques need to be applied on the trained network.
-
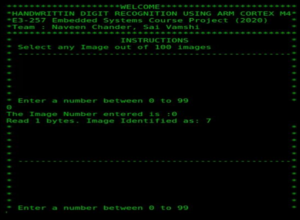
Handwritten Digit Recognition API
For fast inference, the model is optimized using various techniques such as Principle Component Analysis (PCA) ,Quantization and multiplier-less optimization.
- Optimized model is implemented on Cortex-M4 micro-controller in Tiva Board.
- Input images to the model on Tiva board are sent via UART interface from a Linux Host PC.
- An API is written in C to interface Linux Host with Tiva board.
- A total of 100 images (indexed 0 – 99) are given as a part of the API source code for testing and evaluating the model
Data handling
The dataset is taken form [1].It has a training set of 60000 images and a test set of 10000 images.Each image is a 28*28 greyscale image with pixel values from 0-255.First the pixel value is normalised in the range of 0-1.Then each image is flattened to give 784 input features where each feature is in the range of 0-1.This 784 features can be reduced further by performing Principal Component Analysis.This preprocessed data is used for training as well as testing.
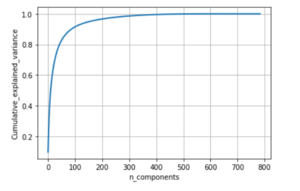
cumulative variance
PCA
Principal component Analysis is a technique useful for dimensionality reduction.Here we find the best smaller subspace upon which if the data is projected it retains most of the variance from the original dataset.The best subspace is represented by the eigen vectors corresponding to the highest eigen values of the data covariance matrix.All of this carried out on TensorFlow.On this dataset PCA was caarried out.The graph below shows the cumulative variance explained by the different number of features.It can be seen that with just 300 features instead of 784 features 100% variance in the data is retained.Therefore the features added after the most significant 300 features do not give any additional information thus can be neglected.In our implementation we have used 100 features which retains around 92% of variance from the original dataset and the loss in accuracy is less than 1% when compared to the network with 784 features.In this way the number of parameters in the network would reduced by 85%.That is 21000 parameters are reduced to around 3800 with less than 1% drop in accuracy.
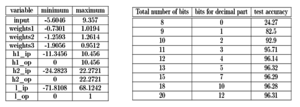
quantisation Results
Quantization
The final trained network with learnt parameters to be implemented on the board needs to be converted to fixed point.The fixed point analysis is carried out in MATLAB and results are as follows.All the intermediate values are found and based on these the number system is selected.The best fit would be using 12 bits for the representation with 8 bits for integer and 4 bits for fractional part. For implementation on cortex we can make use of short.

Weights quantisation scheme
Multiplier-less Implementation
In the above image we can see that all the weights are in the range of -2 to 2.In a neural network main operation is multiplication.If the multiplication opeartion can be reduced to shifting operation then we can save a lot of time in inference and also save considerable power while inferencing which is very useful in Edge AI applications.In order to this we need to quantise the weights into powers of two.The number of bits used for weights effect the accuracy because more the number of bits more number of weights available for quantisation.The best number of bits were found to be 8 bits where 1 bit is for sign another bit is for integer part and the remaining six bits are for fractional part.In this way we will have 15 different weights.So now instead of using short datatype for representing weigths we can just use char datatype to represent the weights using indexes and perform shift operation according to the index.The quantisation is performed according to the image shown below.
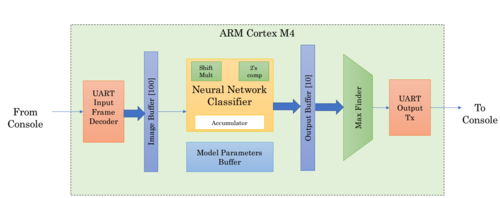
Implementation Block Diagram
Implementation
- The PCA-reduced with image along with header size=104 Bytes is downloaded onto the the micro-controller through UART (UART0 port of Cortex-M4) upon user request to the API software. Once the image is classified, the classified digit is sent back as an ASCII character through the same UART port.
Header
Each image is consists of 100 bytes in int8_t (8-bit integer) format. In order to facilitate reliable transmission of the one complete image frame, it it prefixed with a header of 4 bytes. For every image transmitted from the host the header sequence, 0xAA55BB66 is prefixed to the image, thus resulting in a total of 104 UART byte transmissions from host to the micro-controller. In the micro-controller software, the header decoder is implemented as a finite-state-machine that detects this sequence. Upon detection of this sequence, the micro-controller prepares to receive the image via UART.
Processing
- Each byte of a 100 byte image buffer filled in the UART0_ISR().
- Once the image buffer is filled, the 4-layer neural network classifier procedure – ann(img_buf,output) is initiated.
- All computations in the image classifier routine are carried out in terms of int16_t integers.
- A special multiplication routine is written to carry out signed multiplications using shift operators.
- Output of the neural network classifier is a 10 dimensional vector consisting the likelihood for each digit 0-9.
- The max_finder() function outputs the index of the vector element that has the maximum value of likelihood. This number is sent as ASCII character via UART0 port to the host PC.
Application Program Interface
- Written in C , it accepts an index number between 0 and 99 from the user and sends the corresponding image to Tivaboard via UART.
- It uses <termios.h> library functions to send and receive data through USB port in the Host PC
UART Configuration
- Baud rate : 9600 baud
- UART Frame: 1 start bit, 1 stop bit, 0 parity
- Flow Control : Both Hardware and Software Flowcontrol disabled
- Canonical Mode: Disabled
- SIGINT Characters : Disabled
- VMIN=0, VTIME=10 : During read, the serial port has a time-out of 1 second (10 deci-seconds). If no data is received in the serial port read buffer during this interval, serial port read terminates.
Profiling Result
The Neural Network execution time was found out by profiling. Latency = 284152 clock cycles of 16 Mhz clock , which works out to be 17.76 ms
Conclusion
Artificial Neural network to recognize digits has been implemented on Tivaboard. A near real-time performance has been achieved.
Future Work
- Camera interface and image pre-proccessing: Camera can be interface with Tivaboard through USB and the user-written digit captured by the camera needs to be pre-processed on Tivaboard to reduce it into 100 bytes.
- Alphabet Recognition : Create own datasets for alphabets and train a neural network on similar grounds and implement it on TivaBoard
- Hard real-time performance : Techniques like Binary Neural Network, Ternary Trained Quantization can be applied to further compress the neural network can enable hard real time performance
Recent Comments